@@ -248,7 +248,7 @@ $$L_{\text{MSE}} = \frac{1}{n}\sum_{i=1}^{n}\left(y_{i} - f(x_{i})\right)^{2}$$
248248- $$
249249\begin{align}
250250L_{\text{MSE}} &= \frac{1}{n}\sum_{i=1}^{n}(y_{i} - f(x_{i}))^{2}\\
251- &= \frac{1}{n}\sum_{i=1}^{n}(y_{i} - mx_{i} + c)^{2}
251+ &= \frac{1}{n}\sum_{i=1}^{n}(y_{i} - mx_{i} - c)^{2}
252252\end{align}
253253$$
254254<!-- - Loss: \$\frac{1}{n}\sum_{i=1}^{n}(y_{i} - x_{i})^{2}$ -->
@@ -365,7 +365,7 @@ Image source: [3Blue1Brown](https://www.3blue1brown.com/topics/neural-networks)
365365- See the PyTorch website: [ https://pytorch.org/ ] ( https://pytorch.org/ )
366366
367367
368- # Resources
368+ # Other resources
369369
370370- [ coursera.org/machine-learning-introduction] ( https://www.coursera.org/specializations/machine-learning-introduction/?utm_medium=coursera&utm_source=home-page&utm_campaign=mlslaunch2022IN )
371371- [ uvadlc] ( https://uvadlc-notebooks.readthedocs.io/en/latest/ )
@@ -395,124 +395,127 @@ Image source: [Palmer Penguins by Alison Horst](https://allisonhorst.github.io/p
395395- [ https://github.com/allisonhorst/palmerpenguins ] ( https://github.com/allisonhorst/palmerpenguins )
396396
397397
398- # Part 2: Fun with CNNs
399398
400399
401- ## Convolutional neural networks (CNNs): why? {.smaller}
402400
403- Advantages over simple ANNs:
401+ <!-- # Part 2: Fun with CNNs -->
404402
405- - They require far fewer parameters per layer.
406- - The forward pass of a conv layer involves running a filter of fixed size over the inputs.
407- - The number of parameters per layer _ does not_ depend on the input size.
408- - They are a much more natural choice of function for * image-like* data:
409403
410- :::: {.columns}
411- ::: {.column width=10%}
412- :::
413- ::: {.column width=35%}
404+ <!-- ## Convolutional neural networks (CNNs): why? {.smaller} -->
414405
415- ![ ] ( https://machinelearningmastery.com/wp-content/uploads/2019/03/Plot-of-the-First-Nine-Photos-of-Dogs-in-the-Dogs-vs-Cats-Dataset.png )
406+ <!-- Advantages over simple ANNs: -->
416407
417- :::
418- ::: {.column width=10%}
419- :::
420- ::: {.column width=35%}
408+ <!-- - They require far fewer parameters per layer. -->
409+ <!-- - The forward pass of a conv layer involves running a filter of fixed size over the inputs. -->
410+ <!-- - The number of parameters per layer _does not_ depend on the input size. -->
411+ <!-- - They are a much more natural choice of function for *image-like* data: -->
421412
422- ![ ] ( https://machinelearningmastery.com/wp-content/uploads/2019/03/Plot-of-the-First-Nine-Photos-of-Cats-in-the-Dogs-vs-Cats-Dataset.png )
413+ <!-- :::: {.columns} -->
414+ <!-- ::: {.column width=10%} -->
415+ <!-- ::: -->
416+ <!-- ::: {.column width=35%} -->
423417
424- :::
425- ::::
418+ <!--  -->
426419
427- ::: {.attribution}
428- Image source: [ Machine Learning Mastery] ( https://machinelearningmastery.com/how-to-develop-a-convolutional-neural-network-to-classify-photos-of-dogs-and-cats/ )
429- :::
420+ <!-- ::: -->
421+ <!-- ::: {.column width=10%} -->
422+ <!-- ::: -->
423+ <!-- ::: {.column width=35%} -->
430424
425+ <!--  -->
431426
432- ## Convolutional neural networks (CNNs): why? {.smaller}
427+ <!-- ::: -->
428+ <!-- :::: -->
433429
434- Some other points:
430+ <!-- ::: {.attribution} -->
431+ <!-- Image source: [Machine Learning Mastery](https://machinelearningmastery.com/how-to-develop-a-convolutional-neural-network-to-classify-photos-of-dogs-and-cats/) -->
432+ <!-- ::: -->
435433
436- - Convolutional layers are translationally invariant:
437- - i.e. they don't care _ where_ the "dog" is in the image.
438- - Convolutional layers are _ not_ rotationally invariant.
439- - e.g. a model trained to detect correctly-oriented human faces will likely fail on upside-down images
440- - We can address this with data augmentation (explored in exercises).
441434
435+ <!-- ## Convolutional neural networks (CNNs): why? {.smaller} -->
442436
443- ## What is a (1D) convolutional layer? {.smaller}
437+ <!-- Some other points: -->
444438
445- ![ ] ( 1d-conv.png )
439+ <!-- - Convolutional layers are translationally invariant: -->
440+ <!-- - i.e. they don't care _where_ the "dog" is in the image. -->
441+ <!-- - Convolutional layers are _not_ rotationally invariant. -->
442+ <!-- - e.g. a model trained to detect correctly-oriented human faces will likely fail on upside-down images -->
443+ <!-- - We can address this with data augmentation (explored in exercises). -->
446444
447- See the [ ` torch.nn.Conv1d ` docs] ( https://pytorch.org/docs/stable/generated/torch.nn.Conv1d.html )
448445
446+ <!-- ## What is a (1D) convolutional layer? {.smaller} -->
449447
450- ## 2D convolutional layer {.smaller}
448+ <!--  -->
451449
452- - Same idea as in on dimension, but in two (funnily enough).
450+ <!-- See the [`torch.nn.Conv1d` docs](https://pytorch.org/docs/stable/generated/torch.nn.Conv1d.html) -->
453451
454- ![ ] ( 2d-conv.png )
455452
456- - Everthing else proceeds in the same way as with the 1D case.
457- - See the [ ` torch.nn.Conv2d ` docs] ( https://pytorch.org/docs/stable/generated/torch.nn.Conv2d.html ) .
458- - As with Linear layers, Conv2d layers also have non-linear activations applied to them.
453+ <!-- ## 2D convolutional layer {.smaller} -->
459454
455+ <!-- - Same idea as in on dimension, but in two (funnily enough). -->
460456
461- ## Typical CNN overview {.smaller}
457+ <!--  -->
462458
463- ::: {layout="[ 0.5, 0.5 ] "}
459+ <!-- - Everthing else proceeds in the same way as with the 1D case. -->
460+ <!-- - See the [`torch.nn.Conv2d` docs](https://pytorch.org/docs/stable/generated/torch.nn.Conv2d.html). -->
461+ <!-- - As with Linear layers, Conv2d layers also have non-linear activations applied to them. -->
464462
465- ![ ] ( https://miro.medium.com/v2/resize:fit:1162/format:webp/1*tvwYybdIwvoOs0DuUEJJTg.png )
466463
467- - Series of conv layers extract features from the inputs.
468- - Often called an encoder.
469- - Adaptive pooling layer:
470- - Image-like objects $\to$ vectors.
471- - Standardises size.
472- - [ `` torch.nn.AdaptiveAvgPool2d `` ] ( https://pytorch.org/docs/stable/generated/torch.nn.AdaptiveAvgPool2d.html )
473- - [ `` torch.nn.AdaptiveMaxPool2d `` ] ( https://pytorch.org/docs/stable/generated/torch.nn.AdaptiveMaxPool2d.html )
474- - Classification (or regression) head.
464+ <!-- ## Typical CNN overview {.smaller} -->
475465
476- :::
466+ <!-- ::: {layout="[ 0.5, 0.5 ]"} -->
477467
478- - For common CNN architectures see [ `` torchvision.models `` docs ] ( https://pytorch.org/vision/stable/models.html ) .
468+ <!-- 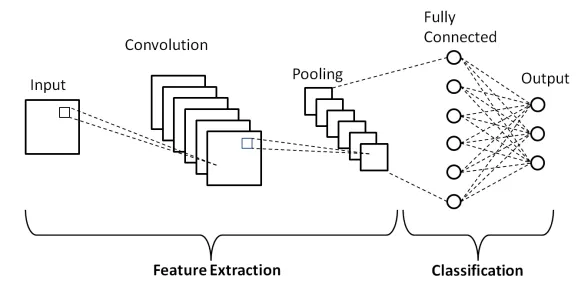 -->
479469
480- ::: {.attribution}
481- Image source: [ medium.com - binary image classifier cnn using tensorflow] ( https://medium.com/techiepedia/binary-image-classifier-cnn-using-tensorflow-a3f5d6746697 )
482- :::
470+ <!-- - Series of conv layers extract features from the inputs. -->
471+ <!-- - Often called an encoder. -->
472+ <!-- - Adaptive pooling layer: -->
473+ <!-- - Image-like objects $\to$ vectors. -->
474+ <!-- - Standardises size. -->
475+ <!-- - [``torch.nn.AdaptiveAvgPool2d``](https://pytorch.org/docs/stable/generated/torch.nn.AdaptiveAvgPool2d.html) -->
476+ <!-- - [``torch.nn.AdaptiveMaxPool2d``](https://pytorch.org/docs/stable/generated/torch.nn.AdaptiveMaxPool2d.html) -->
477+ <!-- - Classification (or regression) head. -->
483478
479+ <!-- ::: -->
484480
485- # Exercises
481+ <!-- - For common CNN architectures see [``torchvision.models`` docs](https://pytorch.org/vision/stable/models.html). -->
486482
487- ## Exercise 1 -- classification
483+ <!-- ::: {.attribution} -->
484+ <!-- Image source: [medium.com - binary image classifier cnn using tensorflow](https://medium.com/techiepedia/binary-image-classifier-cnn-using-tensorflow-a3f5d6746697) -->
485+ <!-- ::: -->
488486
489- ### MNIST hand-written digits.
490487
491- ::: {layout=" [ 0.5, 0.5 ] "}
488+ <!-- # Exercises -->
492489
493- ![ ] ( https://i.ytimg.com/vi/0QI3xgXuB-Q/hqdefault.jpg )
490+ <!-- ## Exercise 1 -- classification -->
494491
495- - In this exercise we'll train a CNN to classify hand-written digits in the MNIST dataset.
496- - See the [ MNIST database wiki] ( https://en.wikipedia.org/wiki/MNIST_database ) for more details.
492+ <!-- ### MNIST hand-written digits. -->
497493
498- :::
494+ <!-- ::: {layout="[ 0.5, 0.5 ]"} -->
499495
500- ::: {.attribution}
501- Image source: [ npmjs.com] ( https://www.npmjs.com/package/mnist )
502- :::
496+ <!--  -->
503497
498+ <!-- - In this exercise we'll train a CNN to classify hand-written digits in the MNIST dataset. -->
499+ <!-- - See the [MNIST database wiki](https://en.wikipedia.org/wiki/MNIST_database) for more details. -->
504500
501+ <!-- ::: -->
505502
506- ## Exercise 2---regression
507- ### Random ellipse problem
503+ <!-- ::: {.attribution} -->
504+ <!-- Image source: [npmjs.com](https://www.npmjs.com/package/mnist) -->
505+ <!-- ::: -->
508506
509- - In this exercise, we'll train a CNN to estimate the centre $(x_ {\text{c}}, y_ {\text{c}})$ and the $x$ and $y$ radii of an ellipse defined by
510- $$
511- \frac{(x - x_{\text{c}})^{2}}{r_{x}^{2}} + \frac{(y - y_{\text{c}})^{2}}{r_{y}^{2}} = 1
512- $$
513507
514- - The ellipse, and its background, will have random colours chosen uniformly on $\left[ 0,\ 255\right] ^{3}$.
515- - In short, the model must learn to estimate $x_ {\text{c}}$, $y_ {\text{c}}$, $r_ {x}$ and $r_ {y}$.
508+
509+ <!-- ## Exercise 2---regression -->
510+ <!-- ### Random ellipse problem -->
511+
512+ <!-- - In this exercise, we'll train a CNN to estimate the centre $(x_{\text{c}}, y_{\text{c}})$ and the $x$ and $y$ radii of an ellipse defined by -->
513+ <!-- $$ -->
514+ <!-- \frac{(x - x_{\text{c}})^{2}}{r_{x}^{2}} + \frac{(y - y_{\text{c}})^{2}}{r_{y}^{2}} = 1 -->
515+ <!-- $$ -->
516+
517+ <!-- - The ellipse, and its background, will have random colours chosen uniformly on $\left[0,\ 255\right]^{3}$. -->
518+ <!-- - In short, the model must learn to estimate $x_{\text{c}}$, $y_{\text{c}}$, $r_{x}$ and $r_{y}$. -->
516519
517520
518521<!-- # Further information -->
0 commit comments