| timezone | UTC+8 |
|---|
- 以太坊初学者
- 你认为你会完成本次残酷学习吗?可以
- Telegram:@stephkuove
目前,需要 2-3 个 epoch(15 分钟左右)才能最终确定(finalize)一个区块,且需要 32 ETH 才能成为质押者。 最初这是为了在以下三个目标之间取得平衡而做出的妥协:
1、最大化参与到质押中的验证者数量
2、最小化最终确定时间
3、最小化运行节点的开销,包括下载、验证和广播其他验证者签名的成本
这三个目标是相互冲突的
希望在理想情况下,保持经济终结性,同时在两个方面改善现状:
1、在单时隙内最终确定区块(理想情况下,保持甚至减少当前 12 秒的时长),而不是 15 分钟
2、允许验证者以 1 ETH 进行质押(原为 32 ETH)
存在的挑战 更快的区块最终确定和更民主化质押的目标,但这都与最小化开销的目标相冲突。
如何做到 单时隙最终性涉及使用一种共识算法来最终确定一个时隙中的区块。 以太坊的独特特性需求是 inactivity leaks:即使超过 1/3 的验证器离线,该特性也允许链继续运行并最终恢复, 已经有提案修改了 Tendermint 共识以适应 inactivity leaks。
问题最难的部分是在验证者数量非常多时,单时隙的最终确定性如何正常工作,而不会导致节点的运营商产生极高的开销。 为此,有几种领先的解决方案 暴力破解 Orbit 委员会 —— 一种新机制,允许随机选取的中型委员会来负责链的最终确定性,但这是以一种我们想要的保留攻击成本特性的方式。 双层质押 —— 一种有两类质押者的机制,一类质押者有较高的存款要求,另一类质押者有较低的存款要求。
还有什么要做,需要权衡什么? 有四种主要的可能路径可供选择(我们也可以采取混合路径):
1、维持现状
2、暴力破解 SSF
3、Orbit SSF
4、有双层质押机制的 SSF
可以组合多种策略,例如:
(1+2):添加 Orbit,但不进行单时隙最终确定。 (1+3):使用强力技术减少最小存款规模,而无需进行单时隙最终确定。所需的聚合量比单纯使用(3)情况少 64 倍,这样一来问题变得更简单了。 (2+3):使用保守参数(例如 128k 验证者委员会而不是 8k 或 32k)执行 Orbit SSF,并使用暴力破解技术使其极其高效。 (1+4):增加彩虹质押而不执行单时隙最终确定
哪个验证者将提出下一个区块是可以预知。会产生一个安全漏洞:攻击者可以进行 DoS 攻击。
如何做到
隐藏哪个验证者将生成下一个区块的信息,至少在区块实际生成之前要隐藏这些信息。 如果删除“单独”这一要求,一种解决方案是让任何人都可以创建下一个区块,但要求 randao 揭示小于 2^256 / N。平均而言,只有一个验证者能够满足此要求 —— 但有时会有两个或更多,有时会没有。
单一秘密领袖选举协议通过使用一些加密技术为每个验证者创建一个“盲”验证者 ID 来解决这个问题,然后让许多提议者有机会对盲 ID 池进行改组和重新盲化(这类似于混合网络的工作方式)。在每个时段,都会选择一个随机盲 ID。只有该盲 ID 的所有者才能生成有效的证明来提议区块,且没有人知道该盲 ID 对应的是哪个验证者。
Dan Boneh 的论文(Paper by Dan Boneh)(2020):https://eprint.iacr.org/2020/025.pdf
Whisk(以太坊具体提案,2022):https://ethresear.ch/t/whisk-a-practical-shuffle-based-ssle-protocol-for-ethereum/11763
在 ethresear.ch 的单一秘密领袖选举标签(Single secret leader election tag on ethresear.ch):https://ethresear.ch/tag/single-secret-leader-election
使用环签名的简化 SSLE(Simplified SSLE using ring signatures):https://ethresear.ch/t/simplified-ssle/12315
需要找到并实现一个足够简单的协议,以便轻松地在主网上实现。我们高度重视保持以太坊协议的简易性,不希望进一步增加复杂性。 SSLE 仅用了数百行规范代码,并在复杂的加密中引入了新的假设。如何实现足够有效的抗量子 SSLE 也是一个问题。
最终可能会出现这样的情况: 只有当我们出于其他原因(例如状态树、ZK-EVM)大胆尝试并在 L1 的以太坊协议中引入执行通用零知识证明的机制时,SSLE 的“边际额外复杂性”才会下降到足够低的水平。
另一种选择是根本不理会 SSLE,而是使用协议外缓解措施(例如在 p2p 层)来解决 DoS 问题。
它如何与路线图的其他部分互动?
如果我们添加证明者-提议者分离(APS)机制,比如执行票证,因为我们可以依赖专门的区块构建器,那么执行区块(例如包含以太坊交易的区块)将不再需要 SSLE。不过,对于共识区块(包含协议消息的区块:比如证明、可能还有纳入列表的一些片段等),我们仍然可以从 SSLE 中受益。
进一步缩短以太坊的交易确认时间(从 12 秒缩短到 4 秒)。 这样做将显著改善 L1 和基于 rollups 的用户体验,同时使 De-Fi 协议更加高效。 它还将使 L2 更易去中心化,因为它将允许大量 L2 应用程序在 based rollups 上运作,从而减少 L2 构建自己的基于委员会的去中心化排序的需求。
这里大致有两种技术:
减少时隙时间,降至如 8 秒或 4 秒。这并不一定意味着 4 秒的最终确定性:最终确定性本质上需要三轮通信,因此我们可以将每轮通信设为一个单独的区块,这将在 4 秒后至少得到初步确认。
允许提议者在单时隙期间发布预确认。在极端情况下,提议者可以实时将他们看到的交易纳入其区块,并立即为每笔交易发布预确认消息。 提议者发布两个相互冲突的确认的情况可以通过两种方式处理: (i)通过罚没(slashing)提议者 (ii)通过使用证明人(attesters)投票选出哪一个更早。
与现有研究有?
Geth:由以太坊基金会直接资助的团队维护,使用 Go 语言开发,是公认的最稳定、久经考验的客户端 Nethermind:由 Nethermind 团队开发和维护,使用 C# 语言开发,早期获以太坊基金会和 Gitcoin 社区资助 Besu:最初由 ConsenSys 的 PegaSys 团队开发,现为 Hyperledger 社区项目,使用 Java 语言开发 Erigon:由 Erigon 团队开发和维护,获以太坊基金会、BNB Chain 资助。2017 年从 Geth 分叉而来,目标是提升同步速度和磁盘效率 Reth:由 Paradigm 主导开发,开发语言是 Rust,强调模块化和高性能,目前已经趋近成熟,可以在生产环境使用
可以将以太坊执行层看作是一个由交易驱动的状态机,执行层最基础的职能就是通过 EVM 执行交易来更新状态数据。 除了交易执行之外,还有保存并验证区块和状态数据,运行 p2p 网络并维护交易池等功能。
交易由用户(或者程序)按照以太坊执行层规范定义的格式生成,用户需要对交易进行签名,如果交易是合法的(Nonce 连续、签名正确、gas fee 足够、业务逻辑正确),那么交易最终就会被 EVM 执行,从而更新以太坊网络的状态。这里的状态是指数据结构、数据和数据库的集合,包括外部账户地址、合约地址、地址余额以及代码和数据。
执行层负责执行交易以及维护交易执行之后的状态,共识层负责选择哪些交易来执行。EVM 则是这个状态机中的状态转换函数,函数的输入会来源于多个地方,有可能来源于共识层提供的最新区块信息,也有可能来源于 p2p 网络下载的区块。
共识层和执行层通过 Engine API 来进行通信,这是执行层和共识层之间唯一的通信方式。如果共识层拿到了出块权,就会通过 Engine API 让执行层产出新的区块,如果没有拿到出块权,就会同步最新的区块让执行层验证和执行,从而与整个以太坊网络保持共识。
执行层从逻辑上可以分为 6 个部分:
EVM:负责执行交易,交易执行也是修改状态数的唯一方式 存储:负责 state 以及区块等数据的存储 交易池:用于用户提交的交易,暂时存储,并且会通过 p2p 网络在不同节点之间传播 p2p 网络:用于发现节点、同步交易、下载区块等等功能 RPC 服务:提供访问节点的能力,比如用户向节点发送交易,共识层和执行层之间的交互 BlockChain:负责管理以太坊的区块链数据
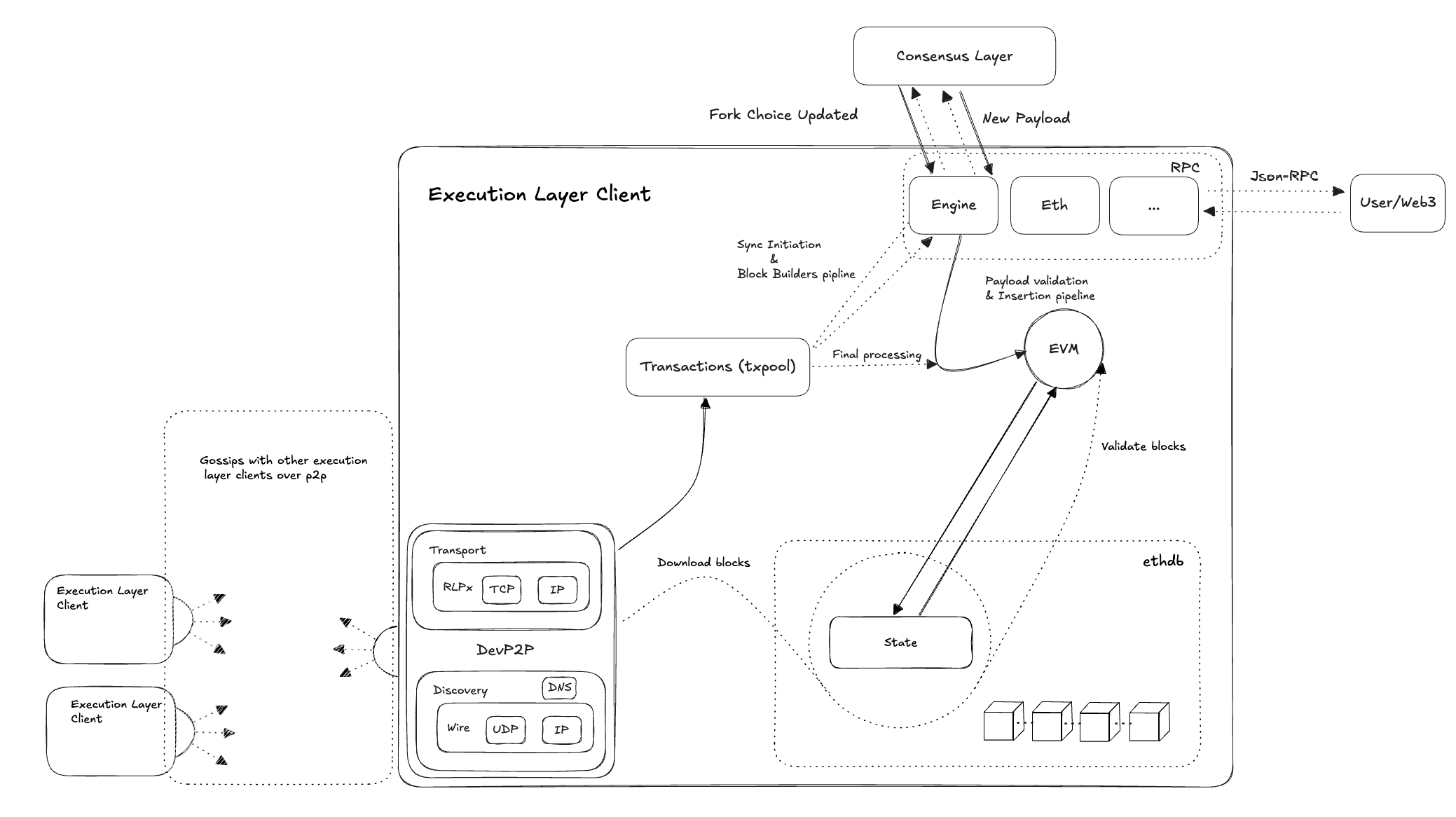
如果是新加入以太坊的节点,需要通过 p2p 网络从其他的节点同步区块和状态数据,如果是 Full Sync,会从创世区块开始逐个下载区块,验证区块并通过 EVM 重建状态数据库,如果是 Snap Sync,则跳过全部区块验证的过程,直接下载最新 checkpoint 的状态数据和以后的区块数据 如果是已经同步到最新状态的节点,那么就会持续通过 Engine API 从共识层获取到当前最新产出的区块,并验证区块,然后通过 EVM 执行区块中所有的交易来更新状态数据库,并将区块写入本地链 如果是已经同步到最新状态,并且共识层拿到了出块权的节点,就会通过 Engine API 驱动执行层产出最新的区块,执行层从交易池获取交易并执行,然后组装成区块通过 Engine API 传递给共识层,由共识层将区块广播到共识层 p2p 网络
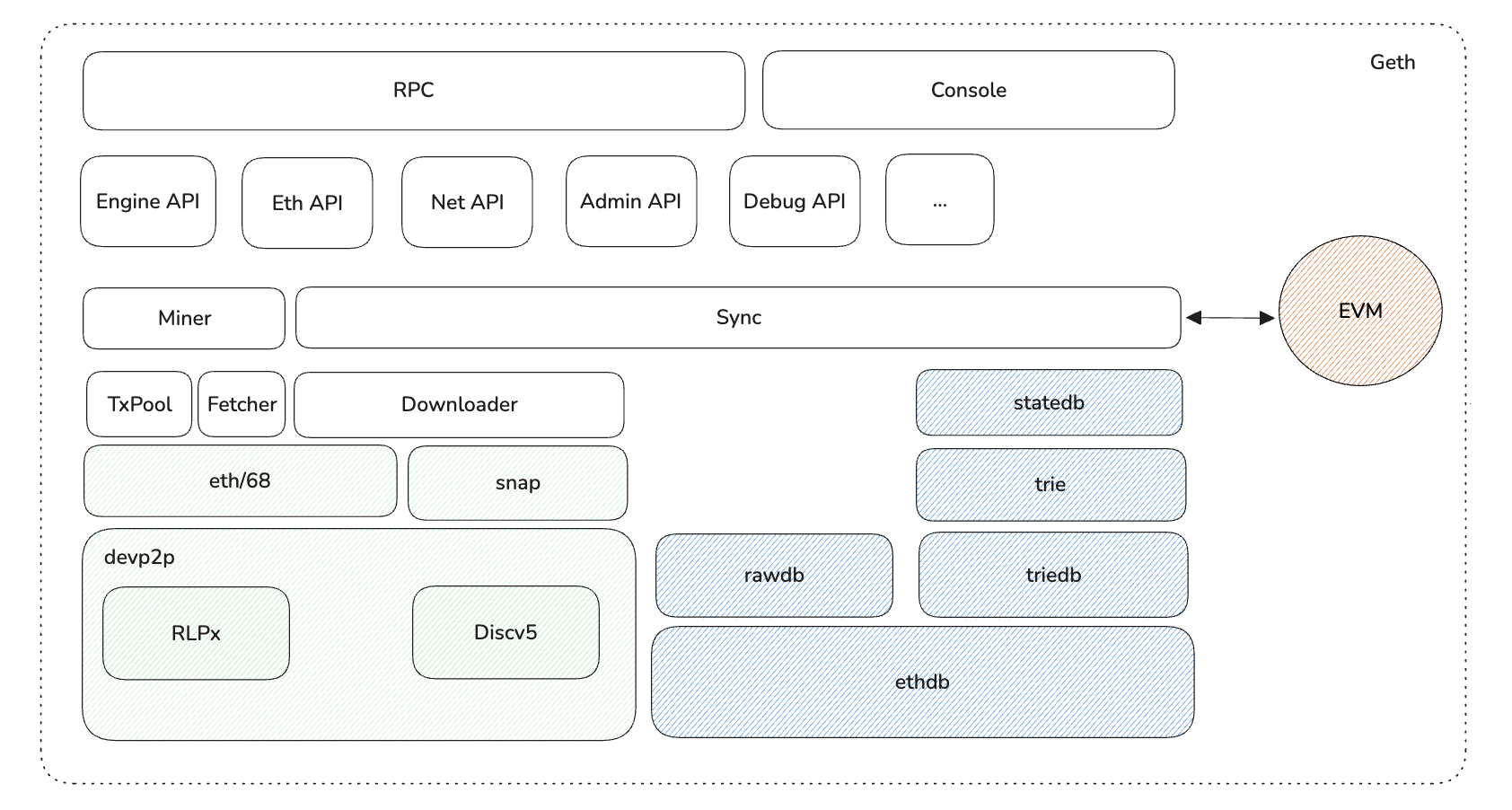
go-ethereum 的代码结构很庞大,但其中很多代码属于辅助代码和单元测试,在研究 Geth 源码时,只需要关注协议的核心实现,各个模块功能如下。 需要重点关注 core、eth、ethdb、node、p2p、rlp、trie & triedb 等模块:
accounts:管理以太坊账户,包括公私钥对的生成、签名验证、地址派生等
beacon:处理与以太坊信标链(Beacon Chain)的交互逻辑,支持权益证明(PoS)共识的合并(The Merge)后功能
build:构建脚本和编译配置(如 Dockerfile、跨平台编译支持)
cmd:命令行工具入口,包含多个子命令
common:通用工具类,如字节处理、地址格式转换、数学函数
consensus:定义consensus engine ,包括之前的工作量证明(Ethash)和单机权益证明(Clique)以及 Beacon engine 等
console:提供交互式 JavaScript 控制台,允许用户通过命令行直接与以太坊节点交互(如调用 Web3 API、管理账户、查询区块链数据)
core:区块链核心逻辑,处理区块/交易的生命周期管理、状态机、Gas计算等
crypto:加密算法实现,包括椭圆曲线(secp256k1)、哈希(Keccak-256)、签名验证
docs:文档(如设计规范、API 说明)
eth:以太坊网络协议的完整实现,包括节点服务、区块同步(如快速同步、归档模式)、交易广播等
ethclient:实现以太坊客户端库,封装 JSON-RPC 接口,供 Go 开发者与以太坊节点交互(如查询区块、发送交易、部署合约)
ethdb:数据库抽象层,支持 LevelDB、Pebble、内存数据库等,存储区块链数据(区块、状态、交易)
ethstats:收集并上报节点运行状态到统计服务,用于监控网络健康状态
event:实现事件订阅与发布机制,支持节点内部模块间的异步通信(如新区块到达、交易池更新)
graphql:提供 GraphQL 接口,支持复杂查询(替代部分 JSON-RPC 功能)
internal:内部工具或限制外部访问的代码
log:日志系统,支持分级日志输出、上下文日志记录
mertrics:性能指标收集(Prometheus 支持)
miner:挖矿相关逻辑,生成新区块并打包交易(PoW 场景下)
node:节点服务管理,整合 p2p、RPC、数据库等模块的启动与配置
p2p:点对点网络协议实现,支持节点发现、数据传输、加密通信
params:定义以太坊网络参数(主网、测试网、创世区块配置)
rlp:实现以太坊专用的数据序列化协议 RLP(Recursive Length Prefix),用于编码/解码区块、交易等数据结构
rpc:实现 JSON-RPC 和 IPC 接口,供外部程序与节点交互
signer:交易签名管理(硬件钱包集成)
tests:集成测试和状态测试,验证协议兼容性
trie & triedb:默克尔帕特里夏树(Merkle Patricia Trie)的实现,用于高效存储和管理账户状态、合约存储
外部访问 Geth 节点有两种形式,一种是通过 RPC,另外一种是通过 Console。 RPC 适合开放给外部的用户来使用,Console 适合节点的管理者使用。但无论是通过 RPC 还是 Console,都是使用内部已经封装好的能力,这些能力通过分层的方式来构建。
最外层是 API 用于外部访问节点的各项能力, Engine API 用于执行层和共识层之间的通信,Eth API 用于外部用户或者程序发送交易,获取区块信息,Net API 用于获取 p2p 网络的状态等等。 比如用户通过 API 发送了一个交易,那么这个交易最终会被提交到交易池中,通过交易池来管理,再比如用户需要获取一个区块数据,那么就需要调用数据库的能力去获取对应的区块。
在 API 的下一层就核心功能的实现,包括交易池、交易打包、产出区块、区块和状态的同步等等。
这些功能再往下就需要依赖更底层的能力,比如交易池、区块和状态的同步需要依赖 p2p 网络的能力,区块的产生以及从其他节点同步过来的区块需要被验证才能写入到本地的数据库,这些就需要依赖 EVM 和数据存储的能力。
在 eth/backend.go 中的 Ethereum 结构是整个以太坊协议的抽象,基本包括了以太坊中的主要组件,但 EVM 是一个例外,它会在每次处理交易的时候实例化,不需要随着整个节点初始化,下文中的 Ethereum 都是指这个结构体:
type Ethereum struct {
// 以太坊配置,包括链配置
config *ethconfig.Config
// 交易池,用户的交易提交之后先到交易池
txPool *txpool.TxPool
// 用于跟踪和管理本地交易(local transactions)
localTxTracker *locals.TxTracker
// 区块链结构
blockchain *core.BlockChain
// 是以太坊节点的网络层核心组件,负责处理所有与其他节点的通信,包括区块同步、交易广播和接收,以及管理对等节点连接
handler *handler
// 负责节点发现和节点源管理
discmix *enode.FairMix
// 负责区块链数据的持久化存储
chainDb ethdb.Database
// 负责处理各种内部事件的发布和订阅
eventMux *event.TypeMux
// 共识引擎
engine consensus.Engine
// 管理用户账户和密钥
accountManager *accounts.Manager
// 管理日志过滤器和区块过滤器
filterMaps *filtermaps.FilterMaps
// 用于安全关闭 filterMaps 的通道,确保在节点关闭时正确清理资源
closeFilterMaps chan chan struct{}
// 为 RPC API 提供后端支持
APIBackend *EthAPIBackend
// 在 PoS 下,与共识引擎协作验证区块
miner *miner.Miner
// 节点接受的最低gas价格
gasPrice *big.Int
// 网络 ID
networkID uint64
// 提供网络相关的 RPC 服务,允许通过 RPC 查询网络状态
netRPCService *ethapi.NetAPI
// 管理P2P网络连接,处理节点发现和连接建立并提供底层网络传输功能
p2pServer *p2p.Server
// 保护可变字段的并发访问
lock sync.RWMutex
// 跟踪节点是否正常关闭,在异常关闭后帮助恢复
shutdownTracker *shutdowncheck.ShutdownTracker
}
在 node/node.go 中的 Node 是另一个核心的数据结构,它作为一个容器,负责管理和协调各种服务的运行。 在下面的结构中,需要关注一下 lifecycles 字段,Lifecycle 用来管理内部功能的生命周期。比如上面的 Ethereum 抽象就需要依赖 Node 才能启动,并且在 lifecycles 中注册。这样可以将具体的功能与节点的抽象分离,提升整个架构的扩展性,这个 Node 需要与 devp2p 中的 Node 区分开。
type Node struct {
eventmux *event.TypeMux
config *Config
// 账户管理器,负责管理钱包和账户
accman *accounts.Manager
log log.Logger
keyDir string
keyDirTemp bool
dirLock *flock.Flock
stop chan struct{}
// p2p 网络实例
server *p2p.Server
startStopLock sync.Mutex
// 跟踪节点生命周期状态(初始化、运行中、已关闭)
state int
lock sync.Mutex
// 所有注册的后端、服务和辅助服务
lifecycles []Lifecycle
// 当前提供的 API 列表
rpcAPIs []rpc.API
// 为 RPC 提供的不同访问方式
http *httpServer
ws *httpServer
httpAuth *httpServer
wsAuth *httpServer
ipc *ipcServer
inprocHandler *rpc.Server
databases map[*closeTrackingDB]struct{}
}
如果以一个抽象的维度来看以太坊的执行层,以太坊作为一台世界计算机,需要包括三个部分,网络、计算和存储,那么以太坊执行层中与这三个部分相对应的组件是:
网络:devp2p
计算:EVM
存储:ethdb
以太坊本质还是一个分布式系统,每个节点通过 p2p 网络与其他节点相连。以太坊中的 p2p 网络协议的实现就是 devp2p。
devp2p 有两个核心功能, 一个是节点发现,让节点在接入网络时能够与其他节点建立联系; 另一个是数据传输服务,在与其他节点建立联系之后,就可以想换交换数据。
在 p2p/enode/node.go 中的 Node 结构代表了 p2p 网络中一个节点,其中 enr.Record 结构中存储了节点详细信息的键值对,包括身份信息(节点身份所使用的签名算法、公钥)、网络信息(IP 地址,端口号)、支持的协议信息(比如支持 eth/68 和 snap 协议)和其他的自定义信息,这些信息通过 RLP 的方式编码,具体的规范在 eip-778 中定义:
type Node struct {
// 节点记录,包含节点的各种属性
r enr.Record
// 节点的唯一标识符,32字节长度
id ID
// hostname 跟踪节点的DNS名称
hostname string
// 节点的IP地址
ip netip.Addr
// UDP端口
udp uint16
// TCP端口
tcp uint16
}
// enr.Record
type Record struct {
// 序列号
seq uint64
// 签名
signature []byte
// RLP 编码后的记录
raw []byte
// 所有键值对的排序列表
pairs []pair
}
在 p2p/discover/table.go 中的 Table 结构是 devp2p 实现节点发现协议的核心数据结构,它实现了类似 Kademlia 的分布式哈希表,用于维护和管理网络中的节点信息。
type Table struct {
mutex sync.Mutex
// 按距离索引已知节点
buckets [nBuckets]*bucket
// 引导节点
nursery []*enode.Node
rand reseedingRandom
ips netutil.DistinctNetSet
revalidation tableRevalidation
// 已知节点的数据库
db *enode.DB
net transport
cfg Config
log log.Logger
// 周期性的处理网络中的各种事件
refreshReq chan chan struct{}
revalResponseCh chan revalidationResponse
addNodeCh chan addNodeOp
addNodeHandled chan bool
trackRequestCh chan trackRequestOp
initDone chan struct{}
closeReq chan struct{}
closed chan struct{}
// 增加和移除节点的接口
nodeAddedHook func(*bucket, *tableNode)
nodeRemovedHook func(*bucket, *tableNode)
}
ethdb 完成以太坊数据存储的抽象,提供统一的存储接口,底层具体的数据库可以是 leveldb,也可以是 pebble 或者其他的数据库。可以有很多的扩展,只要在接口层面保持统一。
有些数据(如区块数据)可以通过 ethdb 接口直接对底层数据库进行读写,其他的数据存储接口都是建立的 ethdb 的基础上,比如数据库有很大部分的数据是状态数据,这些数据会被组织成 MPT 结构,在 Geth 中对应的实现是 trie,在节点运行的过程中,trie 数据会产生很多中间状态,这些数据不能直接调用 ethdb 进行读写,需要 triedb 来管理这些数据和中间状态,最后才通过 ethdb 来持久化。
在 ethdb/database.go 中定义底层数据库的读写能力的接口,但没有包括具体的实现,具体的实现将由不同的数据库自身来实现。比如 leveldb 或者 pebble 数据库。在 Database 中定义了两层数据读写的接口,其中 KeyValueStore 接口用于存储活跃的、可能频繁变化的数据,如最新的区块、状态等。AncientStore 则用于处理历史区块数据,这些数据一旦写入就很少改变。
// 数据库的顶层接口
type Database interface {
KeyValueStore
AncientStore
}
// KV 数据的读写接口
type KeyValueStore interface {
KeyValueReader
KeyValueWriter
KeyValueStater
KeyValueRangeDeleter
Batcher
Iteratee
Compacter
io.Closer
}
// 处理老数据的读写的接口
type AncientStore interface {
AncientReader
AncientWriter
AncientStater
io.Closer
}
EVM 是以太坊这个状态机的状态转换函数,所有状态数据的更新都只能通过 EVM 来进行,p2p 网络可以接受到交易和区块信息,这些信息被 EVM 处理之后会成为状态数据库的一部分。EVM 屏蔽了底层硬件的不同,让程序在不同平台的 EVM 上执行都能得到一致的结果。这是一种很成熟的设计方式,Java 语言中 JVM 也是类似的设计。
EVM 的实现有三个主要的组件,core/vm/evm.go 中的 EVM 结构体定义了 EVM 的总体结构及依赖,包括执行上下文,状态数据库依赖等等; core/vm/interpreter.go 中的 EVMInterpreter 结构体定义了解释器的实现,负责执行 EVM 字节码;core/vm/contract.go 中的 Contract 结构体封装合约调用的具体参数,包括调用者、合约代码、输入等等,并且在 core/vm/opcodes.go 中定义了当前所有的操作码:
// EVM
type EVM struct {
// 区块上下文,包含区块相关信息
Context BlockContext
// 交易上下文,包含交易相关信息
TxContext
// 状态数据库,用于访问和修改账户状态
StateDB StateDB
// 当前调用深度
depth int
// 链配置参数
chainConfig *params.ChainConfig
chainRules params.Rules
// EVM配置
Config Config
// 字节码解释器
interpreter *EVMInterpreter
// 中止执行的标志
abort atomic.Bool
callGasTemp uint64
// 预编译合约映射
precompiles map[common.Address]PrecompiledContract
jumpDests map[common.Hash]bitvec
}
type EVMInterpreter struct {
// 指向所属的EVM实例
evm *EVM
// 操作码跳转表
table *JumpTable
// Keccak256哈希器实例,在操作码间共享
hasher crypto.KeccakState
// Keccak256哈希结果缓冲区
hasherBuf common.Hash
// 是否为只读模式,只读模式下不允许状态修改
readOnly bool
// 上一次CALL的返回数据,用于后续重用
returnData []byte
}
type Contract struct {
// 调用者地址
caller common.Address
// 合约地址
address common.Address
jumpdests map[common.Hash]bitvec
analysis bitvec
// 合约字节码
Code []byte
// 代码哈希
CodeHash common.Hash
// 调用输入
Input []byte
// 是否为合约部署
IsDeployment bool
// 是否为系统调用
IsSystemCall bool
// 可用gas量
Gas uint64
// 调用附带的 ETH 数量
value *uint256.Int
}
执行层的功能通过分层的方式来实现,其他的模块和功能都是在这三个核心组件的基础之上构建起来的。 以下是几个核心的模块。
在 eth/protocols 下有当前以太坊的 p2p 网络子协议的实现。有 eth/68 和 snap 子协议,这个些子协议都是在 devp2p 上构建的。
eth/68 是以太坊的核心协议,协议名称就是 eth,68 是它的版本号,然后在这个协议的基础之上又实现了交易池(TxPool)、区块同步(Downloader)和交易同步(Fetcher)等功能。snap 协议用于新节点加入网络时快速同步区块和状态数据的,可以大大减少新节点启动的时间。
ethdb 提供了底层数据库的读写能力,由于以太坊协议中有很多复杂的数据结构,直接通过 ethdb 无法实现这些数据的管理,所以在 ethdb 上又实现了 rawdb 和 statedb 来分别管理区块和状态数据。
EVM 则贯穿所有的主流程,无论是区块构建还是区块验证,都需要用 EVM 执行交易。
Geth 的启动会分为两个阶段,第一阶段会初始化节点所需要启动的组件和资源,第二节点会正式启动节点,然后对外服务。
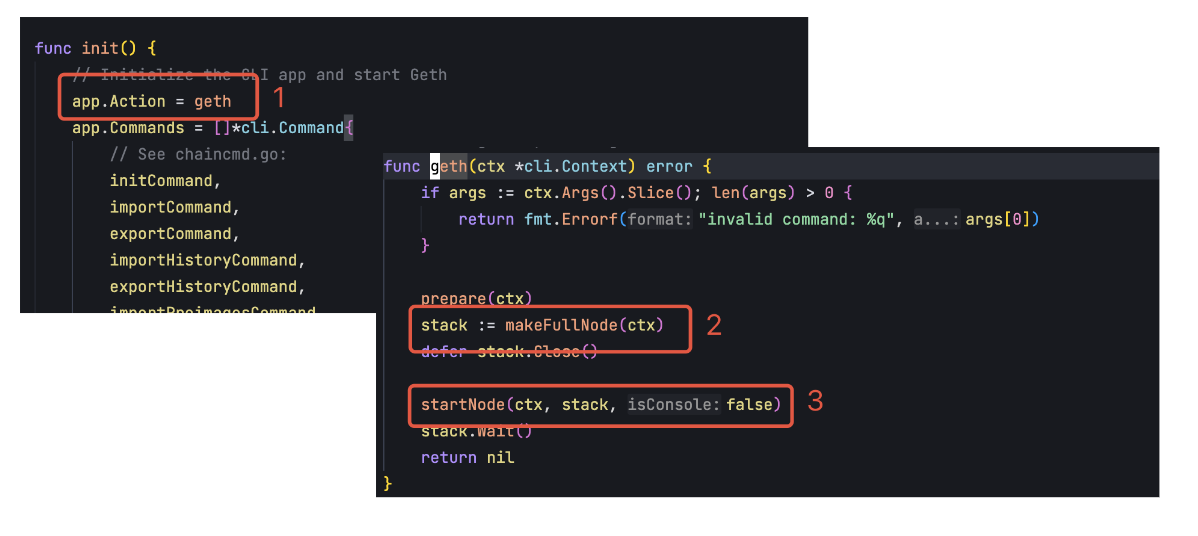
在启动一个 geth 节点时,会涉及到以下的代码:
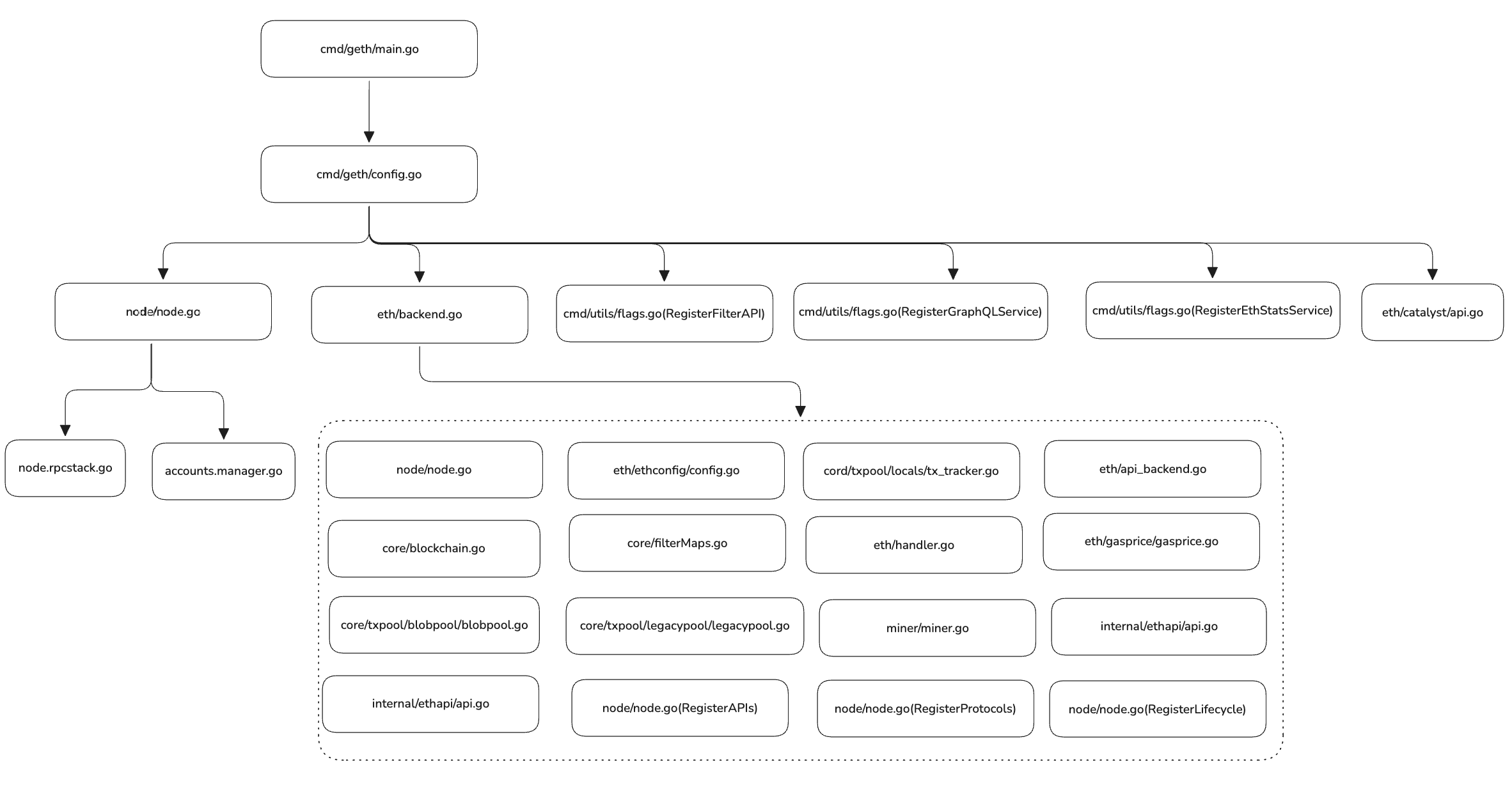
各模块的初始化如下:
cmd/geth/main.go:geth 节点启动入口
cmd/geth/config.go(makeFullNode):加载配置,初始化节点
node/node.go:初始化以太坊节点的核心容器
node.rpcstack.go:初始化 RPC 模块
accounts.manager.go:初始化 accountManager
eth/backend.go:初始化 Ethereum 实例
node/node.go OpenDatabaseWithFreezer:初始化 chaindb
eth/ethconfig/config.go:初始化共识引擎实例(这里的共识引擎并不真正参与共识,只是会验证共识层的结果,以及处理 validator 的提款请求)
core/blockchain.go:初始化 blockchain
core/filterMaps.go:初始化 filtermaps
core/txpool/blobpool/blobpool.go:初始化 blob 交易池
core/txpool/legacypool/legacypool.go:初始化普通交易池
cord/txpool/locals/tx_tracker.go:本地交易追踪(需要配置开启本地交易追踪,本地交易会被更高优先级处理)
eth/handler.go:初始化协议的 Handler 实例
miner/miner.go:实例化交易打包的模块(原挖矿模块)
eth/api_backend.go:实例化 RPC 服务
eth/gasprice/gasprice.go:实例化 gas 价格查询服务
internal/ethapi/api.go:实例化 P2P 网络 RPC API
node/node.go(RegisterAPIs):注册 RPC API
node/node.go(RegisterProtocols):注册 p2p 的 Ptotocols
node/node.go(RegisterLifecycle):注册各个组件的生命周期
cmd/utils/flags.go(RegisterFilterAPI):注册 Filter RPC API
cmd/utils/flags.go(RegisterGraphQLService):注册 GraphQL RPC API(如果配置了的话)
cmd/utils/flags.go(RegisterEthStatsService):注册 EthStats RPC API(如果配置了的话)
eth/catalyst/api.go:注册 Engine API
节点的初始化会在 cmd/geth/config.go 中的 makeFullNode 中完成,重点会初始化以下三个模块:
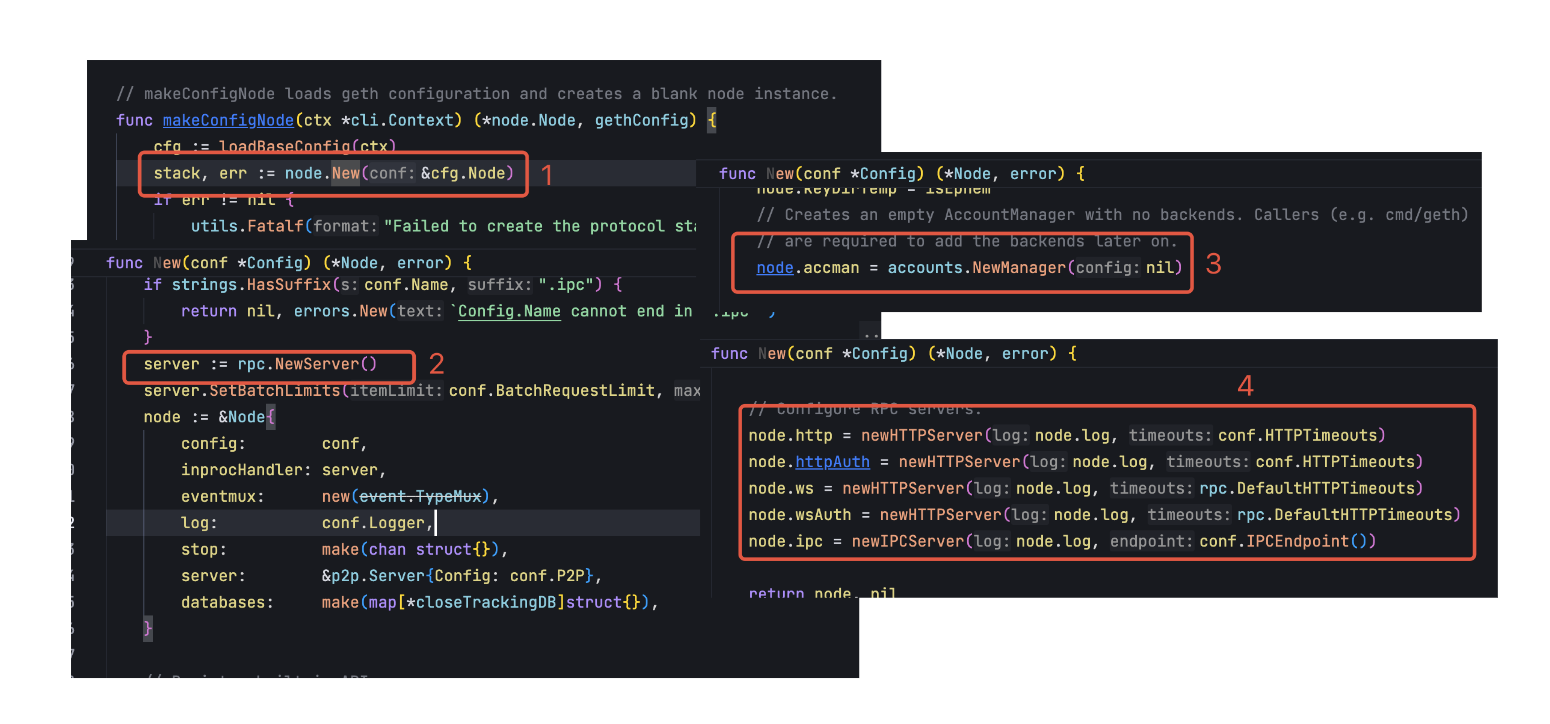
在第一步会初始化 node/node.go 中的 Node 结构,就是整个节点容器,所有的功能都需要在这个容器中运行,第二步会初始化 Ethereum 结构,其中包括以太坊各种核心功能的实现,Etherereum 也需要注册到 Node 中,第三步就是注册 Engine API 到 Node 中。
其中 Node 初始化就是创建了一个 Node 实例,然后初始化 p2p server、账号管理以及 http 等暴露给外部的协议端口。
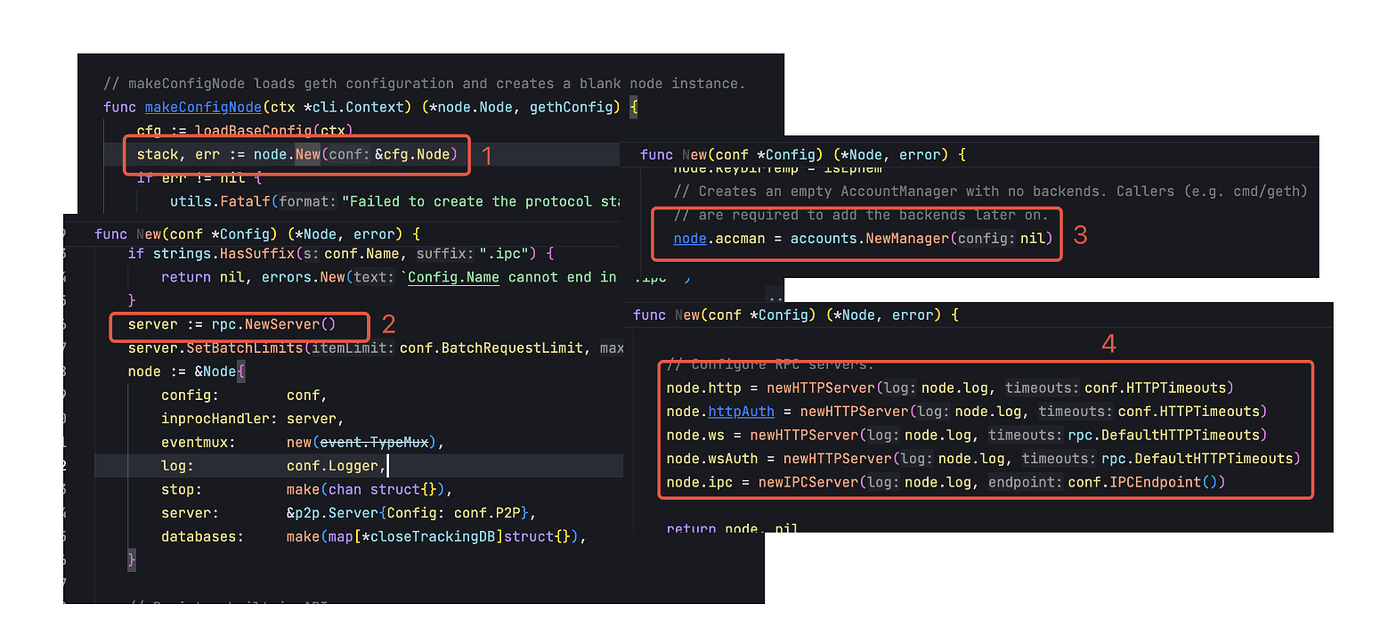
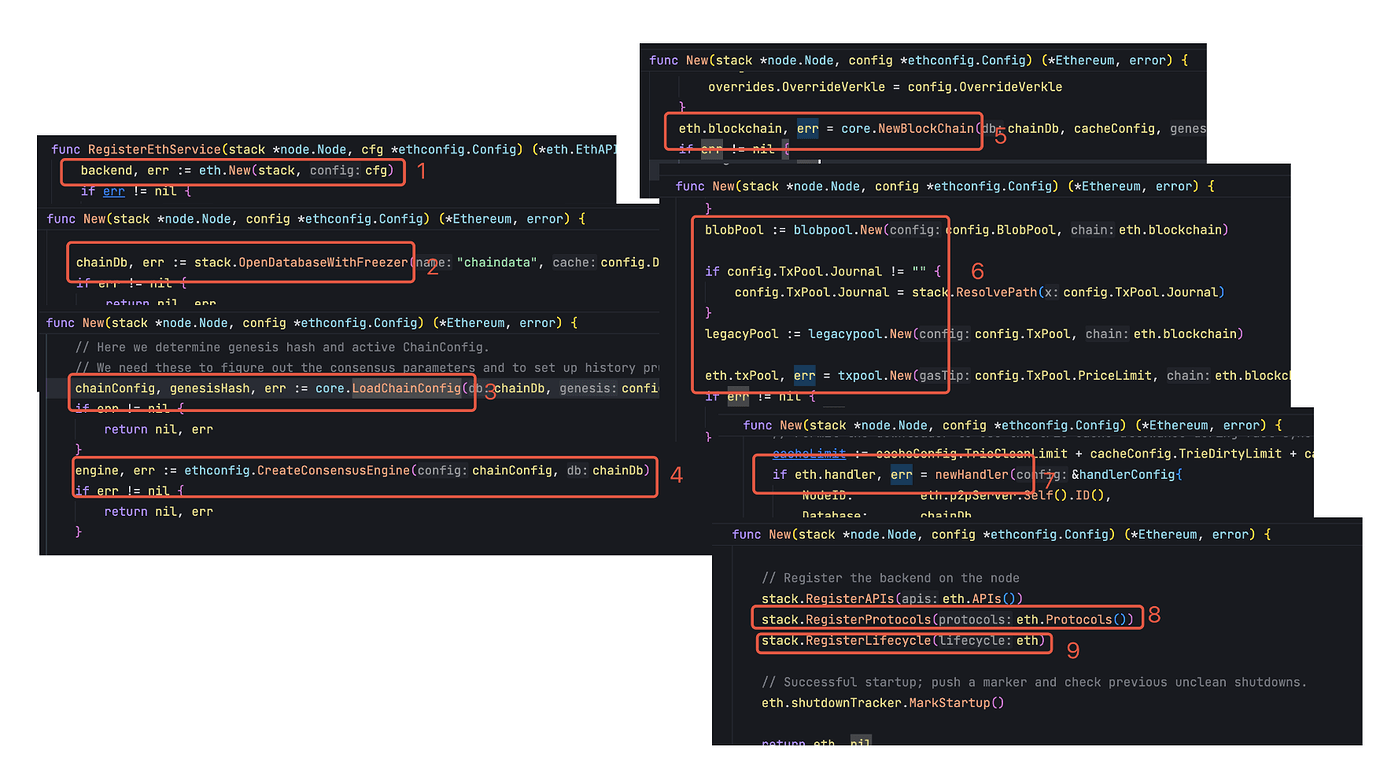
Ethereum 的初始化就会复杂很多,大多数的核心功能都是在这里初始化。首先会初始化化 ethdb,并从存储中加载链配置,然后创建共识引擎,这里的共识引擎不会执行共识操作,而只是会对共识层返回的结果进行验证,如果共识层发生了提款请求,也会在这里完成实际的提款操作。然后再初始化 Block Chain 结构和交易池。
这些都完成之后就会初始化 handler,handler 是所有 p2p 网络请求的处理入口,包括交易同步、区块下载等等,是以太坊实现去中心化运行的关键组件。在这些都完成之后,就会将一些在 devp2p 基础之上实现的子协议,比如 eth/68、snap 等注册到 Node 容器中,最后 Ethereum 会作为一个 lifecycle 注册到 Node 容器中,Ethereum 初始化完成。
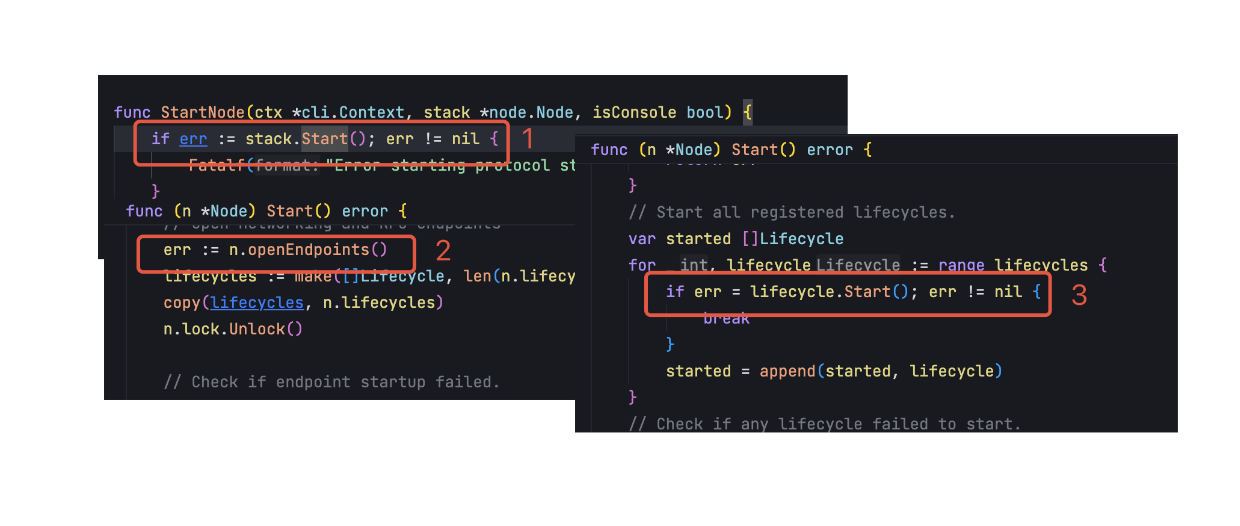
节点启动
在完成节点的初始化之后,就需要启动节点了,节点启动的流程相对简单,只需要将已经注册的 RPC 服务和 Lifecycle 全部启动,那么整个节点就可以向外部提供服务了。
在深入理解以太坊执行层的实现之前,需要对以太坊有一个整体的认识,可以将以太坊整体看作是一个交易驱动的状态机,执行层负责交易的执行和状态的变更,共识层则负责驱动执行层运行,包括让执行层产出区块、决定交易的顺序、为区块投票、以及让区块获得最终性。由于这个状态机是去中心化的,所以需要通过 p2p 网络与其他的节点通信,共同维护状态数据的一致性。
在执行层不负责决定交易的顺序,只负责执行交易并记录交易执行之后的状态变化。这里的记录有两种形式,一种是以区块的方式将所有的状态变化都记录下来,另一种是在数据库中记录当前的状态。同时执行层也是交易的入口,通过交易池来存储还没有被打包进区块的交易。如果其他的节点需要获取区块、状态和交易数据,执行层就会通过 p2p 网络将这些信息发送出去。
对于执行层,有三个核心模块:计算、存储和网络。计算对应 EVM 的实现,存储则对应了 ethdb 的实现,网络对了 devp2p 的实现。有了这样的整体认识之后,就可以深入去理解每一个子模块,而不会迷失在具体的细节中。
Geth 将其数据库分为两部分:快速访问存储(KV 数据库,用于最近的区块和状态数据)和称为 freezer 的存储(用于较旧的区块和收据数据,即“ancients”)。
快速访问存储: Geth 用户可能对底层数据库的选项较为熟悉——可以通过 --db.engine 参数进行配置。目前的默认选项是 pebbledb,也可以选择 leveldb。这两个都是 Geth 所依赖的第三方键值数据库,负责存储路径为 datadir/geth/chaindata(所有的区块和状态数据)和 datadir/geth/nodes(数据库元数据文件,体积很小)的文件。通过 --history.state value 设置快速访问保存的最近历史状态区块数,默认为90,000个区块。
freezer 或 ancients存储(历史数据),其目录路径通常为 datadir/geth/chaindata/ancients。由于历史数据基本是静态的,不需要高性能 I/O,因此可以节省宝贵的 SSD 空间,用于存储更活跃的数据。
本文的重点是状态数据,它存储在 KV 数据库中。因此,文中提到的底层数据库默认是指这个 KV 存储,而非 freezer。
Geth 的底层使用 LevelDB/PebbleDB 存储所有以 RLP 编码后的数据,但其逻辑上划分出五种用途不同的数据库:
| 名称 | 描述 |
|---|---|
| State Trie | 世界状态,包括账户、合约存储 |
| Contract Codes | 合约代码 |
| State snapshot | 世界状态快照 |
| Receipts | 交易收据 |
| Headers/Blocks | 区块数据 |
| 每种数据通过 key 前缀(core/rawdb/schema.go)区分,逻辑上实现职责分离。通过 geth db inspect 可以查看 Geth 存储的所有以太坊数据(块高 22,347,000),可以看到磁盘空间占用最大的是区块、收据和状态数据。 |
Geth 中包含
StateDB、state.Database、trie.Trie、TrieDB、rawdb 和 ethdb 六个数据库模块,
它们如同一棵“状态生命树”的各个层级。最顶层的 StateDB 是 EVM 执行阶段的状态接口,负责处理账户与存储的读写请求,并将这些请求逐层下传,最终由最底层负责物理持久化的 ethdb 读/写物理数据库。
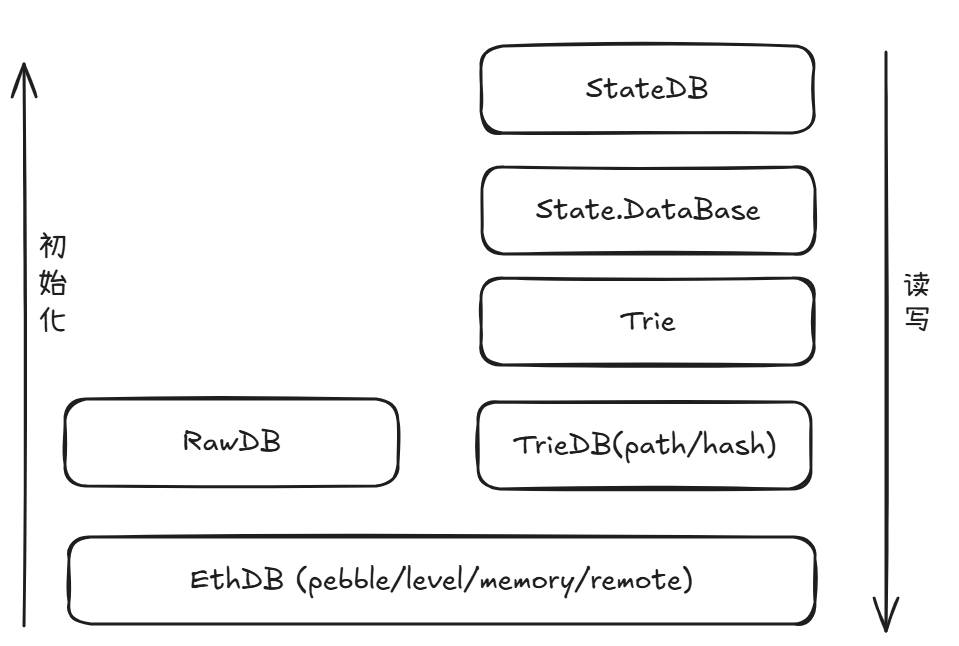
在 Geth 中,StateDB 是 EVM 与底层状态存储之间的唯一桥梁,负责抽象和管理合约账户、余额、nonce、存储槽等信息的读写,对所有其他数据库(TrieDB, EthDB)的状态相关读写都由 StateDB 中的相关接口触发,可以说 StateDB 是所有状态数据库的大脑。 它并不直接操作底层的 Trie 或底层数据库(ethdb),而是提供一个简化的内存视图,让 EVM 能以熟悉的账户模型进行交互。 因此,多数依赖 Geth 的项目其实也不会关心底层的 EthDB 或 TrieDB 是怎么实现的——它们能正常工作就够了,没必要动。大多数基于 Geth 的分叉项目都会修改 StateDB 结构,以适应自己的业务逻辑。例如,Arbitrum 修改了 StateDB 以管理它们的 Stylus 程序;EVMOS 修改了 StateDB 来追踪对其有状态预编译合约(stateful precompile)的调用。
源码中,StateDB 的主要定义位于 core/state/statedb.go。它的核心结构维护了一系列内存状态对象(stateObject),每个 stateObject 对应一个账户(包含合约存储)。它还包含一个 journal(事务日志)用于支持回滚,以及用于追踪状态更改的缓存机制。在交易处理和区块打包过程中,StateDB 提供临时状态变更的记录,只有在最终确认后才会写入底层数据库。
StateDB 的核心读写接口如下,基本都是账户模型相关的 API:
// 读相关
func (s *StateDB) GetBalance(addr common.Address) *uint256.Int
func (s *StateDB) GetStorageRoot(addr common.Address) common.Hash
// 写入dirty状态数据
func (s *StateDB) SetStorage(addr common.Address, storage map[common.Hash]common.Hash)
// 将EVM执行过程中发生的状态变更(dirty数据) commit到后端数据库中
func (s *StateDB) commitAndFlush(block uint64, deleteEmptyObjects bool, noStorageWiping bool) (*stateUpdate, error)
StateDB 的生命周期只持续一个区块。在一个区块被处理并提交之后,这个 StateDB 就会被废弃,不再具有作用
EVM 第一次读取某个地址时,StateDB 会从Trie→TrieDB→EthDB数据库中加载它的值,并将其缓存一个新的状态对象(stateObject.originalStorage)中。这一阶段被视为“干净的对象”(clean object)。
当交易与该账户发生交互并改变其状态时,对象就变成“脏的”(dirty)。stateObject会同时追踪该账户的原始状态和所有修改后的数据,包括其存储槽及其干净/脏状态。
如果整个交易最终成功被打包到区块,StateDB.Finalise() 会被调用。这个函数负责清理已 selfdestruct 的合约,并重置 journal(事务日志)以及 gas refund 计数器。
当所有交易都执行完毕后,StateDB.Commit() 被调用。在这之前,状态树Trie实际上还未被更改。直到这一步,StateDB 才会将内存中的状态变更写入存储 Trie,计算出每个账户的最终 storage root,从而生成账户的最终状态。接下来,所有“脏”的状态对象会被写入 Trie中,更新其结构并计算新的 stateRoot。
最后,这些更新后的节点会被传递给 TrieDB,它会根据不同的后端(PathDB/HashDB)缓存这些节点,并最终将它们持久化到磁盘(LevelDB/PebbleDB)——前提是这些数据没有因为链重组被丢弃。
state.Database 是 Geth 中连接 StateDB 与底层数据库(EthDB 与 TrieDB)的重要中间层,它为状态访问提供了一组简洁的接口和实用方法。虽然它的接口比较薄,但在源码中,它扮演了多个关键角色,尤其是在状态树访问与优化方面。
在 Geth 源码中(core/state/database.go),state.Database 接口由 state.cachingDB 这一具体数据结构实现。它的主要作用包括:
提供统一的状态访问接口 state.Database 是构建 StateDB 的必要依赖,它封装了打开账户 Trie 和存储 Trie 的逻辑,例如:
```
func (db *cachingDB) OpenTrie(root common.Hash) (Trie, error)
func (db *cachingDB) OpenStorageTrie(stateRoot common.Hash, address common.Address, root common.Hash, trie Trie) (Trie, error)
```
这些方法隐藏了底层 TrieDB 的复杂性,开发者在构建某个区块的状态时,只需调用这些方法获取正确的 Trie 实例,而不必直接操作 hash 路径、trie 编码或底层数据库。 暂存和复用合约代码(code cache) 合约代码的访问代价较高,且往往在多个块中重复使用。为此,state.Database 中实现了代码缓存逻辑,避免重复从磁盘加载合约字节码。这一优化对提高区块执行效率至关重要:
func (db *CachingDB) ContractCodeWithPrefix(address common.Address, codeHash common.Hash) []byte
这个接口允许按地址和代码哈希快速命中缓存,若未命中才回退到底层数据库加载。
长生命周期,跨多个区块复用 与 StateDB 的生命周期仅限于单个区块不同,state.Database 的生命周期和整个链(core.Blockchain)保持一致。它在节点启动时构造,并贯穿整个运行周期,作为 StateDB 的“忠实伙伴”,为其在每个区块处理时提供支持。
为未来的 Verkle Tree 迁移做准备 虽然当前 state.Database 看似只是“代码缓存+trie 访问封装”,但它在 Geth 架构中的定位非常前瞻性。一旦未来的状态结构切换至 Verkle Trie,它将成为迁移过程的核心组件:处理新旧结构之间的桥接状态。
在 Geth 中,状态树 Trie(Merkle Patricia Trie)本身并不存储数据,但 Trie 承担计算状态根哈希和收集修改节点的核心职责,并起到衔接 StateDB 与底层存储之间的桥梁作用,是以太坊状态系统的中枢结构。
当 EVM 执行交易或调用合约时,并不会直接操作底层的数据库,而是通过 StateDB 间接与 Trie 交互。Trie 接收账户地址和存储槽位的查询与更新请求,并在内存中构建状态变化路径。这些路径最终通过递归哈希运算,自底向上生成新的根哈希(state root),这个根哈希是当前世界状态的唯一标识,并被写入区块头中,确保状态的完整性和可验证性。
在一个区块执行完毕并进入提交阶段(StateDB.Commit),Trie 会将所有修改过的节点“塌缩”为一个必要的子集,并传递给 TrieDB,由其进一步交由后端的节点数据库(如 HashDB 或 PathDB)持久化。由于 Trie 节点以结构化形式编码,它既支持高效读取,也使得状态在不同节点之间可以安全地同步和验证。因此,Trie 不只是一个状态容器,更是连接上层 EVM 与底层存储引擎的纽带,使得以太坊状态具备一致性、安全性和模块化可扩展性。
源码中,Trie 主要定位于 trie/trie.go 中, 它提供了如下核心接口:
type Trie interface {
GetKey([]byte) []byte
GetAccount(address common.Address) (*types.StateAccount, error)
GetStorage(addr common.Address, key []byte) ([]byte, error)
UpdateAccount(address common.Address, account *types.StateAccount, codeLen int) error
UpdateStorage(addr common.Address, key, value []byte) error
DeleteAccount(address common.Address) error
DeleteStorage(addr common.Address, key []byte) error
UpdateContractCode(address common.Address, codeHash common.Hash, code []byte) error
Hash() common.Hash
Commit(collectLeaf bool) (common.Hash, *trienode.NodeSet)
Witness() map[string]struct{}
NodeIterator(startKey []byte) (trie.NodeIterator, error)
Prove(key []byte, proofDb ethdb.KeyValueWriter) error
IsVerkle() bool
}
以节点查询 trie.get 为例,它会根据节点类型递归地查找账户或合约存储对应的节点,查找时间复杂度是 log(n),n 为路径深度。
func (t *Trie) get(origNode node, key []byte, pos int) (value []byte, newnode node, didResolve bool, err error) {
switch n := (origNode).(type) {
case nil:
return nil, nil, false, nil
case valueNode:
return n, n, false, nil
case *shortNode:
if !bytes.HasPrefix(key[pos:], n.Key) {
// key not found in trie
return nil, n, false, nil
}
value, newnode, didResolve, err = t.get(n.Val, key, pos+len(n.Key))
if err == nil && didResolve {
n.Val = newnode
}
return value, n, didResolve, err
case *fullNode:
value, newnode, didResolve, err = t.get(n.Children[key[pos]], key, pos+1)
if err == nil && didResolve {
n.Children[key[pos]] = newnode
}
return value, n, didResolve, err
case hashNode:
child, err := t.resolveAndTrack(n, key[:pos])
if err != nil {
return nil, n, true, err
}
value, newnode, _, err := t.get(child, key, pos)
return value, newnode, true, err
default:
panic(fmt.Sprintf("%T: invalid node: %v", origNode, origNode))
}
}
TrieDB 是 Trie 与磁盘存储之间的中间层,专注于 Trie 节点的存取与持久化。每一个 Trie 节点(无论是账户信息还是合约的存储槽)最终都会通过 TrieDB 进行读写。
程序启动时会创建一个 TrieDB 实例,在节点关闭时会被销毁。它在初始化时需要传入一个 EthDB 实例,EthDB 实例负责具体的数据持久化操作。
目前,Geth 支持两种 TrieDB 后端实现:
HashDB:传统方式,以哈希为键。
PathDB:新引入的 Path-based 模型(Geth 1.14.0版本后默认配置),以路径信息作为键,优化了更新与修剪性能。
源码中,TrieDB 主要位于 triedb/database.go。
所有的 TrieDB 后端都必须实现一个 database.Reader 接口,其定义如下:
type Reader interface {
Node(owner common.Hash, path []byte, hash common.Hash) ([]byte, error)
}
这个接口提供了基本的节点查询功能,它会根据路径(path)和节点哈希(hash)从 trie 树中定位并返回该节点。注意,返回的是原始字节数组 —— TrieDB 对节点的内容并不关心,也不知道这是不是账户节点、叶子节点还是分支节点(这由上层的 Trie 来解析)。
接口中的 owner 参数用于区分不同的 trie: 如果是账户 trie,则 owner 留空。 如果是合约的存储 trie,则 owner 是该合约的地址,因为每个合约都有自己独立的存储 trie。 换句话说,TrieDB 是底层节点的读写总线,为上层的 Trie 提供统一的接口,不涉及语义,只关心路径和哈希。它让 Trie 与物理存储系统之间解耦,使得不同存储模型可以灵活替换而不影响上层逻辑。
TrieDB 历史上采用的节点持久化方式是:
将每个 Trie 节点的哈希(Keccak256)作为键,将该节点的 RLP 编码作为值,并写入底层的 key-value 存储中。这种方式现在被称为 HashDB。
这种设计方式非常直接,但有几个显著的优点: 支持多棵 Trie 并存:只需知道根哈希,就能遍历恢复整个 Trie。每个账户的存储、账户 Trie、不同历史状态的根哈希都可以分别管理。 子树去重(Subtrie Deduplication):由于相同的子树具有相同的结构和节点哈希,它们在 HashDB 中会自然共享,不需要重复存储。这对于以太坊的大状态树尤为重要,因为大部分状态在区块之间是保持不变的。
要注意的是,普通的 Geth 节点并不会在每个区块之后将 Trie 完整写入磁盘,这种完整持久化只发生在 “归档模式”(--gcmode archive)下,而大多数主网节点并不使用归档模式。 那普通模式下,状态是怎么写入磁盘的呢?实际上,状态更新会先缓存在内存中,延迟写入磁盘。这个机制叫做“延迟刷盘”(delayed flush),触发条件包括: ⏱️ 定时刷盘:默认每隔 5 分钟(等价于处理完约 5 分钟内的区块)会自动写入一次。 💾 缓存容量达到上限:当状态缓存填满,必须刷盘释放内存。 ⛔ 节点关闭时:为了数据完整性,所有缓存都会刷盘。
尽管 HashDB 的结构设计很简单,但它在内存管理方面非常复杂,特别是 对失效节点的垃圾回收机制:假设某个合约在一个区块被创建,在下一个区块就被销毁 —— 此时与该合约有关的状态节点(包括合约账户和其独立的存储 Trie)都已经没用了,如果不清理,它们会白白占用内存。因此,HashDB 设计了引用计数和节点使用追踪机制来判断哪些节点不再使用并从缓存中清除。
PathDB 是 TrieDB 的一种新后端实现。它改变了 Trie 节点在磁盘上持久化和内存中维护的方式。如前所述,HashDB 是通过节点的哈希进行索引存储的。而这种方法让清除(prune)状态中不再使用的部分变得非常困难。为了解决这一长期问题,Geth 引入了 PathDB。 PathDB 与 HashDB 有几个显著区别: Trie 节点在数据库中是按照其路径(path)作为键进行存储的。某账户或 storage key 节点的路径为该账户地址哈希或 storage key 在 trie 树上与其他节点公共前缀部分;某个合约的 storage Trie 中的节点,其路径前缀包含该账户地址哈希。
account trie node key = Prefix(1byte) || COMPACTED(node_path)
storage trie node key = Prefix(1byte) || account hash(32byte) || COMPACTed(node_path)
HashDB 会定期把每个区块的完整状态刷盘。这意味着即使是你并不关心的旧区块,也会残留完整状态。而 PathDB 始终只在磁盘上维护一棵 Trie。每个区块只更新同一棵 Trie。因为使用路径作为键,节点的修改仅需覆盖旧节点即可;被清除的节点也可以安全删除,因为没有其他 Trie 会引用它们。 被持久化的这棵 Trie 并非链的最新头部,而是落后头部至少 128 个区块。最近 128 个区块的 Trie 更改则分别存在内存中,用于应对短链重组(reorg); 如果出现更大的 reorg,PathDB 会利用 freezer 中预存的每个区块的 state diff(状态差异)进行逆应用(rollback),将磁盘状态回滚至分叉点。
在 Geth 中,rawdb 是一个底层数据库读写模块,它直接封装了对状态、区块链数据、Trie 节点等核心数据的存取逻辑,是整个存储系统的基础接口层。它并不直接暴露给 EVM 或业务逻辑层,而是作为内部工具服务于如 TrieDB、StateDB、BlockChain 等模块的持久化操作。rawdb 和 trie 一样,并不直接存储数据本身,它们都是对底层数据库的抽象封装层,负责定义存取规则,而非执行最终的数据落盘或读取。可以把 rawdb 看作是 Geth 的“硬盘驱动器”,它定义了所有核心链上数据的键值格式和访问接口,负责确保不同模块可以统一、可靠地读写数据。虽然在直接开发中很少会使用它,但它是整个 Geth 存储层最基础、最关键的一环。
源码中,rawdb 主要定位于 core/rawdb/accessors_trie.go。rawdb 提供了大量 ReadXxx 和 WriteXxx 等读写方法,用于标准化地访问不同类型的数据。例如: 区块数据(core/rawdb/accessors_chain.go):ReadBlock, WriteBlock, ReadHeader 等 状态数据(core/rawdb/accessors_trie.go):WriteLegacyTrieNode, ReadTrieNode 等 总体元数据:如总难度、最新头区块哈希、创世信息等
这些方法通常以约定好的 key 前缀(如 h 表示 header, b 表示 block, a 表示 AccountTrieNode)组织数据在底层数据库中(LevelDB 或 PebbleDB)。
TrieDB 本身并不直接操作硬盘,它把具体的读写委托给 rawdb。而 rawdb 又会调用更底层的 ethdb.KeyValueStore 接口,这可能是 LevelDB、PebbleDB 或内存数据库。例如,写入 Trie 相关的数据(账户、存储槽等)时:
基于 HashDB 的 Trie 节点采用 rawdb.WriteLegacyTrieNode 等方法负责将以 (hash, rlp-encoded node) 的形式写入数据库。 基于 PathDB 的 Trie 节点则采用 WriteAccountTrieNode, WriteStorageTrieNode 等方法将以(path, rlp-encoded node)的形式写入数据库。
在 Geth 中,ethdb 是整个存储系统的核心抽象,它扮演着“生命之树”的角色——深深扎根于磁盘,向上传递支持至 EVM 与执行层各个组件。 其主要目的是屏蔽底层数据库实现的差异,为整个 Geth 提供统一的键值读写接口。正因如此,Geth 在任意地方都不直接使用具体的数据库(如 LevelDB、PebbleDB、MemoryDB 等),而是通过 ethdb 提供的接口进行数据访问。
源码中,ethdb 主要定位于 ethdb/database.go。ethdb 中最核心的接口是 KeyValueStore(),它定义了常见的键值操作方法:
type KeyValueStore interface {
Has(key []byte) (bool, error)
Get(key []byte) ([]byte, error)
Put(key []byte, value []byte) error
Delete(key []byte) error
}
这套接口非常简洁,覆盖了基础读写操作。而扩展接口 ethdb.Database 则在此基础上加入了对 freezer 冷存储的读写支持(AncientStore),主要用于链数据(如历史区块、交易回执)的管理:新近区块保存在 KV 存储中,较老的则迁移至 freezer。
此外,ethdb 还提供了多种具体实现版本: LevelDB:最早期的默认实现,稳定成熟。 PebbleDB:目前推荐使用的默认实现,更快、资源效率更高。 RemoteDB:用于远程状态访问场景,在轻节点、验证者或模块化执行环境中尤为重要。 MemoryDB:完全内存实现,常用于 dev 模式和单元测试。 这让 Geth 能够灵活地在不同场景间切换存储后端,比如开发调试使用 MemoryDB,主网上线使用 PebbleDB。
每个 Geth 节点启动时,都会创建唯一的 ethdb 实例,这个对象贯穿程序始终,直到节点关闭。在结构设计上,它被注入到 core.Blockchain 中,进而传递到 StateDB、TrieDB 等模块,成为全局共享的数据访问入口。
正因为 ethdb 抽象了底层数据库细节,Geth 的其他组件才能专注于各自的业务逻辑,比如: StateDB 只关心账户和存储槽; TrieDB 只关心如何存储和查找 Trie 节点; rawdb 只关心如何组织链数据的键值布局; 这些上层组件都无需感知数据是存在哪个具体数据库引擎里。
整体创建顺序为 ethdb → rawdb/TrieDB → state.Database → stateDB → trie,源码中具体调用链如下:
【节点初始化阶段】
MakeChain
└── MakeChainDatabase
└── node.OpenDatabaseWithFreezer
└── node.openDatabase
└── node.openKeyValueDatabase
└── newPebbleDBDatabase / remotedb
↓
ethdb.Database
↓
rawdb.Database (封装 ethdb)
└── rawdb.NewDatabaseWithFreezer(ethdb)
↓
trie.Database (TrieDB)
└── trie.NewDatabase(ethdb)
└── backend: pathdb.New(ethdb) / hashdb.New(ethdb)
↓
state.Database (cachingDB)
└── state.NewDatabase(trieDB)
↓
【区块处理阶段】
chain.InsertChain
└── bc.insertChain
└── state.New(root, state.Database)
↓
state.StateDB
└── stateDB.OpenTrie()
└── stateDB.OpenStorageTrie()
↓
trie.Trie / SecureTrie
| DB 模块 | 创建时机 | 生命周期 | 主要职责 |
|---|---|---|---|
| ethdb.Database | 节点初始化 | 程序全程 | 抽象底层存储,统一接口(LevelDB / PebbleDB / Memory) |
| rawdb | 包裹 ethdb 调用 | 不存储数据本身 | 提供区块/receipt/总难度等链数据的读写接口 |
| TrieDB | core.NewBlockChain() | 程序全程 | 缓存+持久化 PathDB/HashDB 节点 |
| state.Database | core.NewBlockChain() | 程序全程 | 封装 TrieDB,合约代码缓存,后期支持 Verkle 迁移\ |
| state.StateDB | 每个区块执行前创建一次 | 区块执行期间 | 管理状态读写,计算状态根,记录状态变更 |
| trie.Trie | 每次账户或 slot 访问时创建 | 临时,不存储数据本身 | 负责 Trie 结构修改和根哈希计算 |
区块执行完毕后 StateDB 会调用 func (s *StateDB) Commit(block uint64, deleteEmptyObjects bool, noStorageWiping bool),并触发如下存储状态更新: 通过 ret, err := s.commit(deleteEmptyObjects, noStorageWiping)收集 Trie 状态树涉及到的所有更新
func (s *StateDB) commit(deleteEmptyObjects bool, noStorageWiping bool) (*stateUpdate, error) {
...
newroot, set := s.trie.Commit(true)
root = newroot
...
}
其中调用到的 trie.Commit 方法会把所有的节点(不论是 short 节点还是 full 节点)塌缩为 hash 节点 t.root = newCommitter(nodes, t.tracer, collectLeaf).Commit(t.root, t.uncommitted > 100),并收集所有脏节点返回给 StateDB StateDB 利用收集到的所有脏节点更新 TrieDB 缓存层: HashDB 在内存中维护了 dirties map[common.Hash]*cachedNode这个对象来缓存这些更新,并更新相应的 trie 节点引用,缓存有大小限制 PathDB 则在内存中维护了 tree *layerTree 这个对象并增加一层 diff 来缓存这些更新,最多可缓存 128 层 diff
func (s *StateDB) commitAndFlush(block uint64, deleteEmptyObjects bool, noStorageWiping bool) (*stateUpdate, error) {
...
// If trie database is enabled, commit the state update as a new layer
if db := s.db.TrieDB(); db != nil {
start := time.Now()
if err := db.Update(ret.root, ret.originRoot, block, ret.nodes, ret.stateSet()); err != nil {
return nil, err
}
s.TrieDBCommits += time.Since(start)
}
...
- 当 HashDB 或 PathDB 缓存超限时,则会触发 flush,通过 rawdb 提供的相关接口将缓存写入 ethdb 的实际持久层: 全节点 HashDB 模式下,由于 key 是 hash,所以同一个账户如果被修改,由于底层数据库通过 key 无法感知是否是同一个账户,不能轻易删除该 key 及其对应的值,否则可能会影响其他账户状态,所以只会把新修改的 KV 写入 DB,而无法删除旧状态,因此全节点状态很难被修剪。例如两个不同的合约地址 A 和 B 实际保存相同的合约代码,他们在 HashDB 中共享同一个(key 为 hash,value 为合约代码)的存储,若 EVM 执行后销毁其中一个合约 A,另外一个合约 B 代码和合约 A 代码在数据库中的 key 一样,所以不能随意删除数据库中 hash 为 key 的值,否则会导致 B 合约后面读取不到该合约代码了。 全节点 PathDB 模式下,由于 key 是 path,所以同一个账户在底层 DB 对应的 key 是一样的,会把同一个账户对应的状态覆盖掉,因此更容易裁剪全节点的状态。因此现在 Geth 全节点默认采用的是 PathDB 模式 由于 归档(archive)节点需要存储每一个区块对应的状态,此时 HashDB 则更具优势,因为不同区块下很多账户的数据实际上并未修改,基于 hash 作为 key 相当于自动具备裁剪的特性;而此时 PathDB 则需要保存每个区块下所有账户的状态,导致状态会超级大,因此 Geth 的 archive 节点只支持 HashDB 模式
假设左边的 Trie 是 MPT 的初始状态,其中红色的是将被修改的节点;右边的则是 MPT 的新状态,绿色表示之前的 4 个红色节点被修改了。
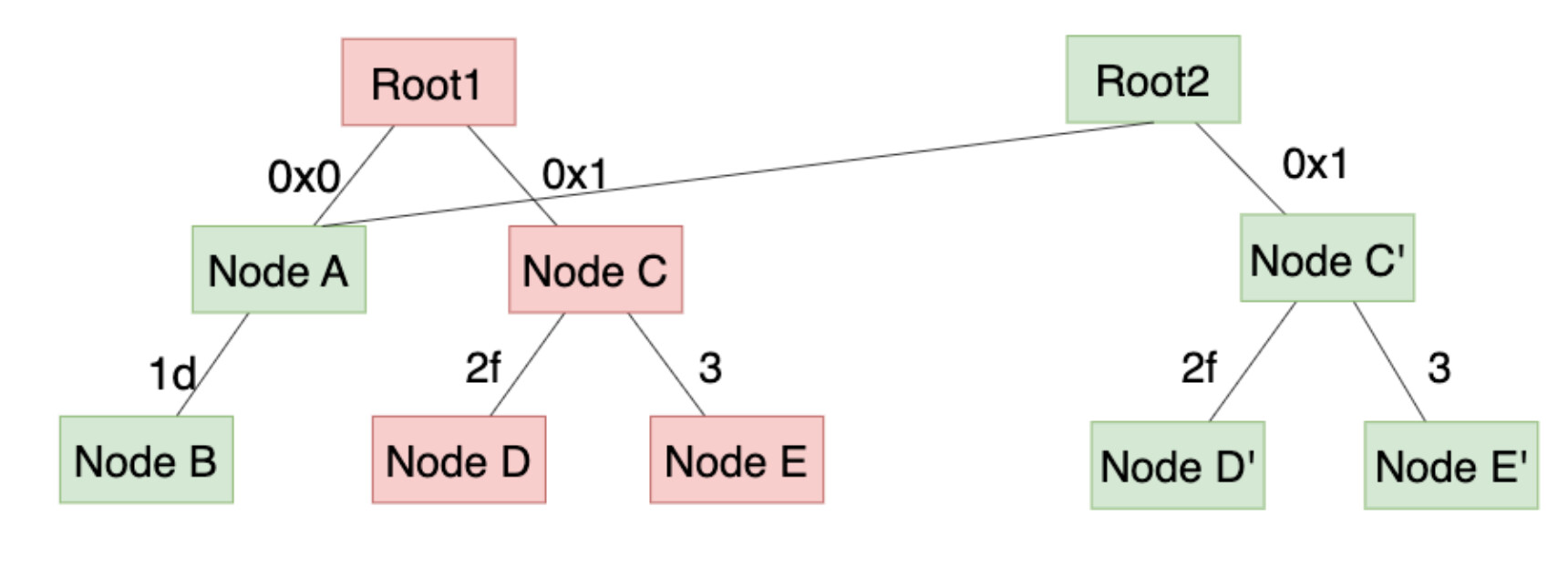
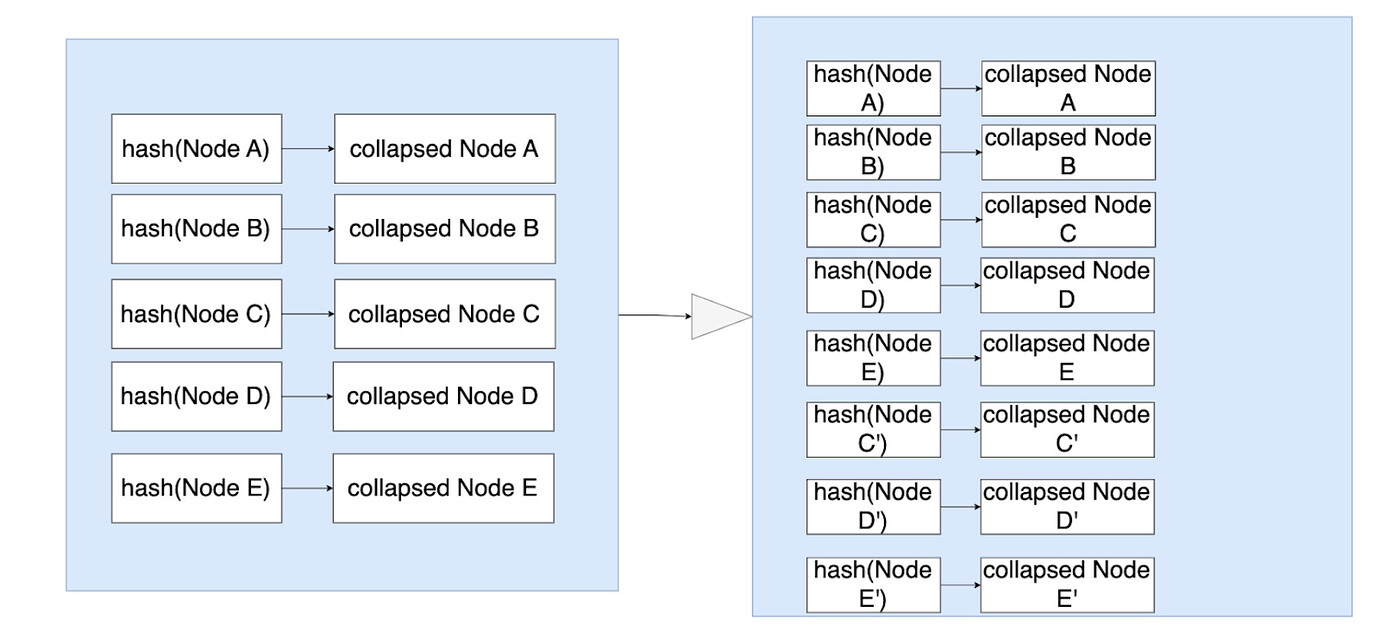
- 在 HashDB 模式下,由于 C/D/E 节点更改后 hash 必定会发生变化,因此尽管 C/D/E 节点对应的三个账户之前已经落盘了,这三个账户对应的新节点 C’/D’/E’ 还是需要落盘,且一旦持久化之后就很难删除这些旧节点了。磁盘更新之前(左图)和之后(右图)的状态如下,其中 collapsed Node 可以简单理解为节点存储的值。
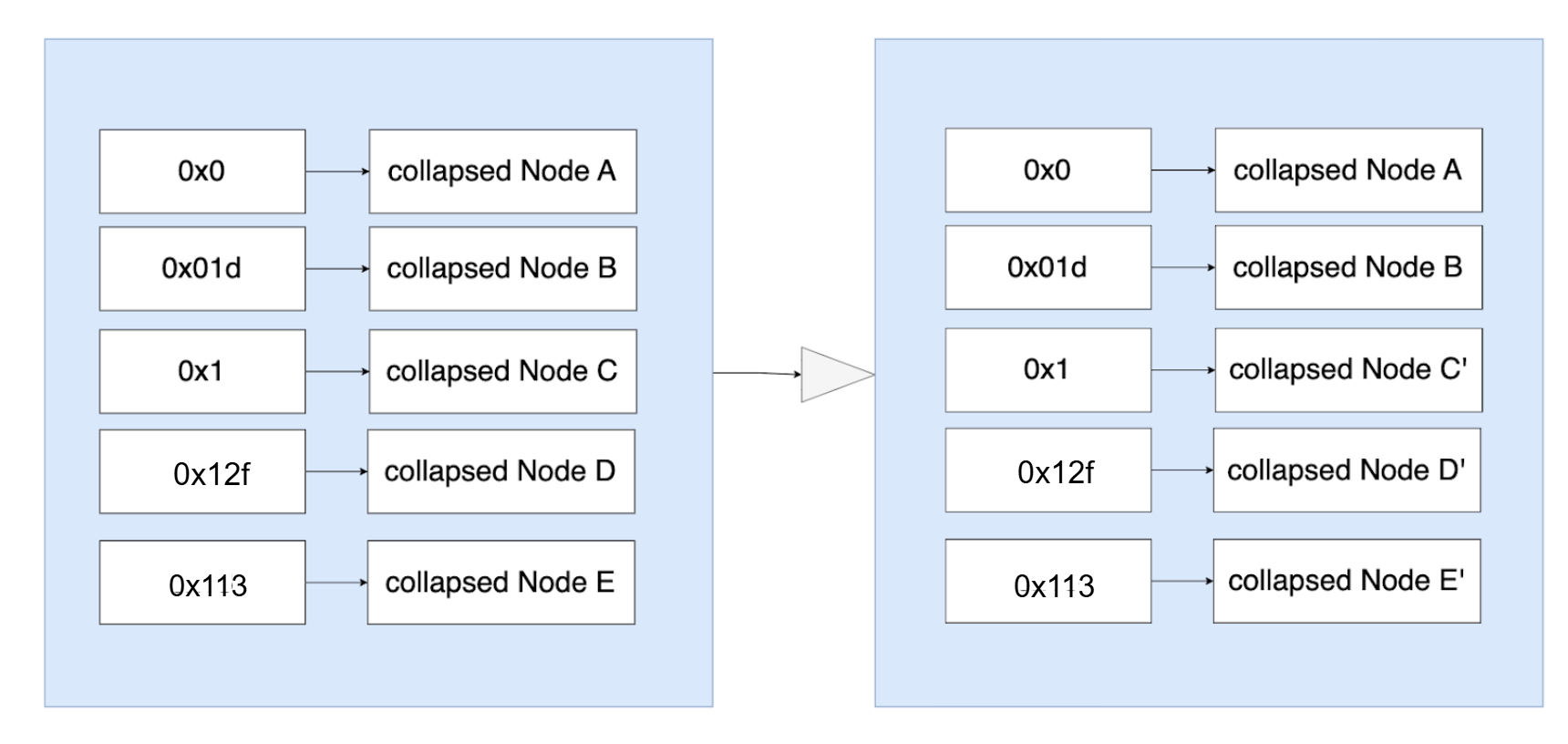
- 在 PathDB 模式下,虽然 C/D/E 节点对应的值发生了变化,但是由于底层存储的 key(path) 不变,在持久化是可以直接替换这三个节点对应的值为 C’/D’/E’ 就可以了,磁盘数据并不会有过多冗余(虽然有些相同的合约可能会在不同的 path 下都保存了一份,但是影响不大)。磁盘更新之前(左图)和之后(右图)的状态如下。
在 core/rawdb/accessors_trie.go 中增加如下 debug 代码,测试 stateDB 读取 0xB3329fcd12C175A236a02eC352044CE44d (account hash:0xaea7c67da6a9bdb230dd07d0e96626e5e57c9cba04dc8039c923baefe55eacd1)涉及到的 Trie 节点数据库读取:
func ReadAccountTrieNode(db ethdb.KeyValueReader, path []byte) []byte {
fmt.Println("PathDB read:", hexutil.Encode(accountTrieNodeKey(path)))
data, _ := db.Get(accountTrieNodeKey(path))
return data
}
func ReadLegacyTrieNode(db ethdb.KeyValueReader, hash common.Hash) []byte {
fmt.Println("HashDB read:", hash)
data, err := db.Get(hash.Bytes())
if err != nil {
return nil
}
return data
}
PathDB 读取到的 Trie 节点如下,可看出读取的是账户地址 hash 的前 8 位相应 path 的节点:
#0x41为前缀,多加的0是nibbles(半字节) 的对齐需要
PathDB read: 0x410a
PathDB read: 0x410a0e
PathDB read: 0x410a0e0a
PathDB read: 0x410a0e0a07
PathDB read: 0x410a0e0a070c
PathDB read: 0x410a0e0a070c06
PathDB read: 0x410a0e0a070c0607
PathDB read: 0x410a0e0a070c06070d
HashDB 读到的 Trie 节点如下,可以看出读取是的 hash 为 key 对应的节点:
HashDB read: 0xb01e32b0c38555bb27f1a924b8408824f97dd8d70f096b218d397906a9095385
HashDB read: 0x99d38ce254e6c35a49504345a30e94b4ea08338279385bae33feaaa11c3a0a00
HashDB read: 0xfcc42d902aa9107b83ee7839a8bc61b370cc5eac9ee60db1af7165daf6c3f76b
HashDB read: 0x3232bc99a88337d2aea2e8c237eb5b4ebb9366ff5bdd94b965ac6f918bd6303f
HashDB read: 0x04ae6f0462f6c0c7e5827dc46fcd69329483d829c39f624744f7b55c09c2cc96
HashDB read: 0x22a16c466cc420e8ed97fd484cecc8f73160ee74a56cfc87ff941d1b56ff46f8
HashDB read: 0xae26238e219065458f314e456265cd9c935e829ba82aebe6d38bacdbb14582f3
HashDB read: 0xe9ce7770c224e563b0c407618b7b7d8614da3d5da89f3960a3bec97e78fc0ae0
HashDB read: 0x2c7d134997a5c3e0bf47ff347479ee9318826f1c58689b3d9caeac77287c3af8
总体来说,PathDB 和 HashDB 均是保持 Trie 数据结构来存储状态数据,只是 PathDB 以 Trie 节点的 path 作为 key,而 HashDB 则是以 Trie 节点值对应的 hash 作为 key,两者均存储值相同均为 Trie 节点的值。
1. 交易执行阶段
- 所有账户和 Storage 值通过 StateDB.GetState 等方法经过 Trie→TrieDB(pathdb/hashdb)→RawDB→Level/PebbleDB 读取到 StateDB 内存中
- 随后 EVM 执行状态变更(如调用 Statedb.SetBalance() )也保留在 StateDB 的内存中
- 包括:余额变更、nonce 更新、storage 修改
2. 单个区块执行完毕更新缓存
- 调用 StateDB.Commit() → 收集脏节点转化为修改的 Trie 节点组,并计算新 StateRoot
- 内部调用 Trie.Commit() → 调用 TrieDB.Update()将更改保存在 TrieDB 缓存层
- PathDB 最多有 128 个块的 diff 缓存层限制
- HashDB 的缓存层有大小限制
- 超过上述限制则进一步触发 TrieDB.Commit 实际落盘到底层数据库
1. 单个区块执行完毕 Header / Receipts 提交:
- 除状态以外,区块头、body、交易回执等数据通过 RawDB.Write*(ethdb) 等接口写入 ethdb 层
2. 多个区块执行后缓存超限触发实际落盘 TrieDB.Commit → batch → DB
- 节点是归档节点 node 或超过 flushInterval 或超过 TrieDB 的缓存限制或节点关闭前,开始触发 commit,并最终落盘。如下是 PathDB 模式下落盘核心代码:
func (db *Database) commit(hash common.Hash, batch ethdb.Batch, uncacher *cleaner) error {
...
rawdb.WriteLegacyTrieNode(batch, hash, node.node) // 多个修改的trie节点加入 batch(未落盘)
if batch.ValueSize() >= ethdb.IdealBatchSize { // 达到 IdealBatchSize 后触发写盘
batch.Write() // 落盘
batch.Replay(uncacher) // 通知 uncacher 清理内存
batch.Reset() // 重置 batch
}
...
Geth 中的这 6 个数据库模块各自承担不同层级的职责,形成了一条自底向上的数据访问链。通过多层抽象与多级缓存,上层模块无需关心底层的具体实现,从而实现了底层存储引擎的可插拔性与较高的 I/O 性能。
最底层的 ethdb 抽象了物理存储,屏蔽具体数据库类型,支持如 LevelDB、Pebble、RemoteDB 等多种后端;其上一层是 rawdb,负责对区块、区块头、交易等核心链上数据结构的编码、解码与封装,简化了链数据的读写操作。TrieDB 管理状态树节点的缓存与持久化,支持 hashdb 与 pathdb 两种后端,用于实现不同的状态修剪策略和存储方式。
再往上,trie.Trie 是状态变化的执行容器与根哈希的计算核心,承担实际的状态构建与遍历操作;state.Database 封装对账户和合约存储 Trie 的统一访问,并提供合约代码缓存;而最顶层的 state.StateDB 是在区块执行过程中与 EVM 对接的接口,提供账户与存储的读缓存和写支持,使得 EVM 无需感知底层 Trie 的复杂结构。
这些模块通过职责分离与接口隔离,协同构建了一个既灵活又高效的状态管理体系,使 Geth 能在复杂链状态与交易执行中保持良好性能与可维护性。
以太坊执行层 p2p 网络功能的实现基于 DevP2P 协议栈所定义的标准,p2p 网络层独立于共识机制(无论是之前的 PoW 还是当前的 PoS,后者由共识层协调)。Geth 的网络架构包含两个并行工作的协议栈:基于 UDP 的发现协议栈(主要用于网络节点间发现)和基于 TCP 的通信协议栈(主要用于节点间数据交换与同步)。
DevP2P 并非指单一协议,而是为以太坊 p2p 网络定制的一套网络协议。 其设计不局限于特定的区块链,但主要服务与以太坊生态的需求。其核心包括:
- 节点发现层: 基于 UDP 协议,用于在 p2p 网络上定位其他以太坊节点。包含如 DiscoveryV4、DiscoveryV5、DNS Discovery 等协议。
- 数据传输层: 基于 TCP 的协议,为节点间提供加密且经过身份验证的通信会话。主要由 RLPx 传输协议提供支持,基于此协议还衍生出多种应用层协议。
- 应用层子协议:在 RLPx 建立的节点发现和安全连接的基础之上,处理节点间的具体数据交互和应用逻辑。这些协议使得节点能够进行区块链同步、交易传播、状态查询等操作。包含如核心的 ETH 协议(Ethereum Wire Protocol)、服务轻客户端的 LES 协议(Light Ethereum Subprotocol)、用于快照同步的 SNAP 协议,以及 WIT(Witness Protocol)、PIP (Parity Light Protocol) 。
以下为 DevP2P 协议栈整体结构图:
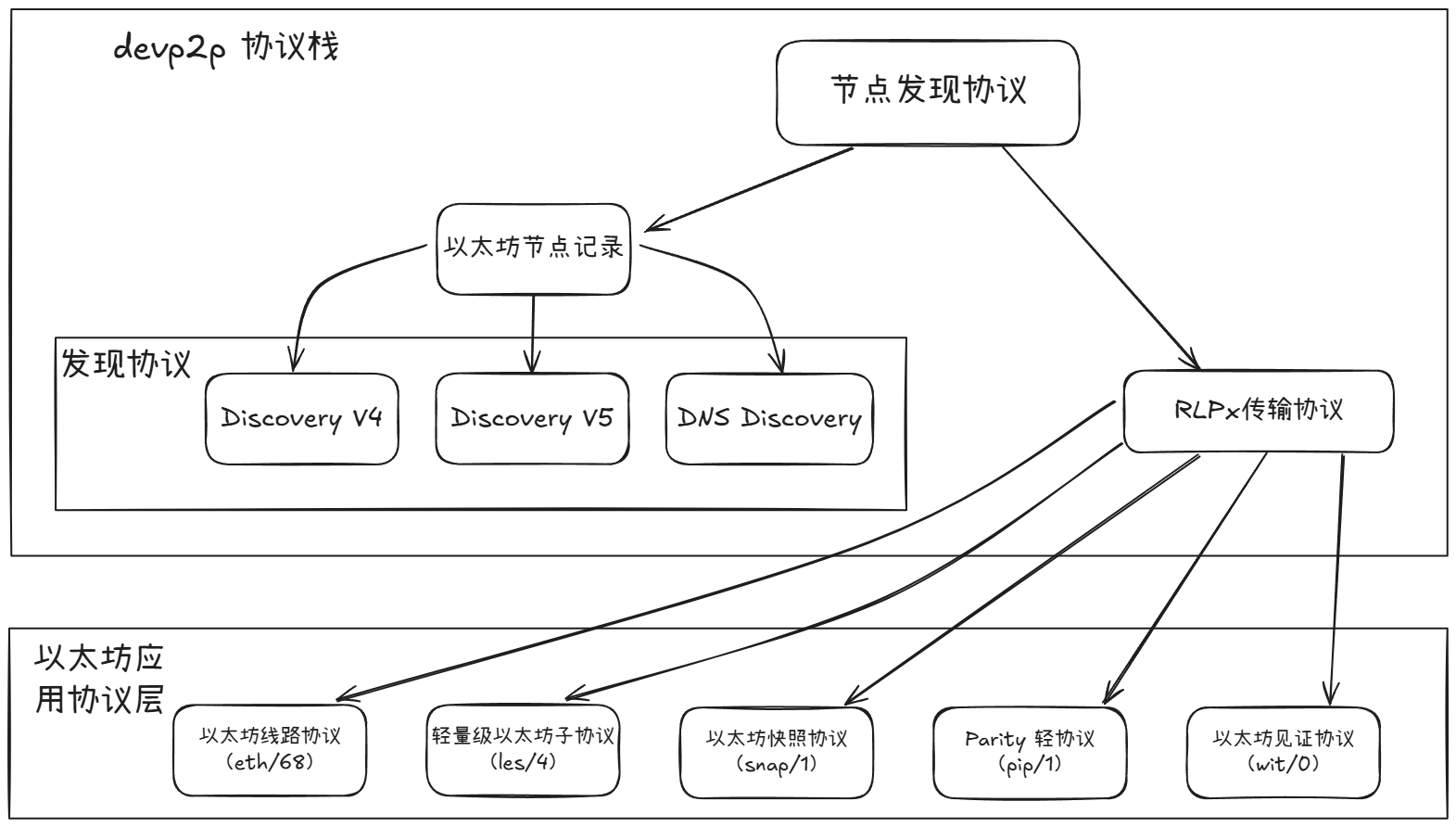
应用层子协议简要说明: 主要功能
| 协议 | 版本 | 主要功能 |
|---|---|---|
| 以太坊线路协议(Ethereum Wire Protocol) | eth/68 | 区块链同步和交易交换的主协议 |
| 以太坊快照协议(Ethereum Snapshot Protocol) | snap/1 | 高效状态快照交换 |
| 轻量级以太坊子协议(Light Ethereum Subprotocol) | les/4 | 轻客户端协议(暂未在 Geth 中实现) |
| Parity 轻协议(Parity Light Protocol) | pip/1 | Parity 对轻客户端的实现(暂未在 Geth 中实现) |
| 以太坊见证协议(Ethereum Witness Protocol) | wit/0 | 节点间见证数据交换(暂未在 Geth 中实现) |
LibP2P(library peer-to-peer)是一个 p2p 网络框架,与以太坊的 DevP2P 在功能定位上有相似之处,它通过一系列协议、规范和库为 p2p 应用的开发提供支持。尽管两者存在相似性,以太坊在其发展初期(约 2014-2015 年)并未选择采用 LibP2P 作为其 P2P 层。
原因是以太坊团队开发 p2p 网络模块(最终形成了 DevP2P)的关键时期,LibP2P 虽然已经作为 IPFS 项目的一部分,但它在当时尚未成熟到能够被以太坊直接集成。为了满足以太坊自身的需求,以太坊的开发者们自行设计和实现了一套 p2p 协议。
与 DevP2P 不同,LibP2P 最开始的核心目标便是构建一个更具普适性、高度模块化的 P2P 网络基础,旨在服务多样化的去中心化应用,而非仅仅应用在某一特定平台或应用场景。
DevP2P 可以被视为一个协议集合,明确定义了以太坊所需的组件,如 ENR、discv5 和 RLPx。而 LibP2P 更像是一个编程库集合,提供了可组合的模块来构建各种 P2P 功能,包括传输、流多路复用、安全通道、节点发现、发布/订阅消息传递等。
目前在以太坊共识层,如 Lighthouse,Prysm,Teku,Nimbus 等客户端,主要采用 LibP2P,共识层利用了 LibP2P 的传输层实现(TCP, QUIC)、加密(Noise)、流多路复用(mplex, yamux)、节点发现(基于 ENR 的 discv5)以及强大的发布/订阅系统(gossipsub)来高效广播证明和区块。
发现协议 V4(Discovery Protocol v4) 发现协议 V4 (简称 DiscV4)是以太坊 DevP2P 协议栈中的核心组件之一,它是一种基于 Kademlia 算法思想的分布式哈希表(DHT),用于网络中的节点发现。Kademlia 的核心机制在于通过节点 ID 间的特定“距离”度量(通过 XOR 异或运算得到)来组织节点,并将其他节点的信息(如 IP 地址、端口和节点 ID)存储到称为“k 桶”(k-buckets)的路由表中。这些信息会被组织为为以太坊节点记录(Ethereum Node Records, ENR),其中包含了节点的网络地址(IP 地址、TCP 与 UDP 端口)、由公钥生成的唯一节点 ID、公钥本身,以及用于验证记录有效性的签名和序列号。
因此,DiscV4 的目标是帮助节点在未知网络中其他节点地址的情况下,能够高效地发现并连接到这些对等节点。这种高效性得益于其迭代查询方法:当一个节点 A 要查找目标节点 B 时,它会向自己 k 桶中已知且 ID “距离”目标 B 最近的一批节点发送查询请求。这些被查询的节点会回复它们各自路由表中离目标 B 更近的节点列表。节点 A 持续向这些新发现的、更近的节点发起查询,逐步逼近目标,通常能在对数时间复杂度(O(log N),其中 N 为网络节点总数)内定位到网络中的任意节点,这远比随机探测或全网广播更为高效且节省网络资源。
发现协议 V5(Discovery Protocol v5)
发现协议 V5(简称 Discv5,当前最新规范为 v5.1)作为对 DiscV4 的重大升级版本,在保留了基于 UDP 的 Kademlia DHT 核心思想(例如通过节点 ID 的 XOR “距离”定义网络拓扑、使用“k 桶”维护路由表,以及通过 PING/PONG 和迭代的 FINDNODE/NODES 消息进行节点发现)的同时,引入了多项关键改进以弥补前代协议在地址管理、信息承载和可扩展性上的不足。其关键更新在于原生实现了以太坊节点记录(ENR,遵循 EIP-778 标准)。
这与 Discv4 后期才通过扩展有限度支持 ENR 不同,DiscV5 将 ENR 作为其基础数据单元,不仅允许 ENR 携带更丰富、可验证的键值对元数据(如支持的协议、特定角色等),而且 ENR 直接包含在常规消息(例如 NODES 响应)中进行交换,无需像 DiscV4 那样需要特定的 ENRRequest。另一项改进是 DiscV5 引入了基于“主题”(Topic)的发现机制;节点可以通过 TOPICREGISTER 消息广播其提供的服务或对特定主题的兴趣,其他节点则能通过 TOPICQUERY 精确查找到这些具有特定能力的对等节点,实现了比 DiscV4 更精细化的服务发现能力。
此外,DiscV5 还定义了全新的、具有更强安全保障的 discv5-wire 底层协议,通过改进握手过程(使用临时密钥和认证标签 AuthTag)来建立加密通信通道,并对消息格式进行了更为严格和清晰的规范。
| 特性 | Discv4 | Discv5 |
|---|---|---|
| ENR 集成与规范基础 | 对 EIP-778 定义的 ENR 支持是后期通过 EIP-868 作为扩展加入的。 | 从设计之初就原生基于 EIP-778 定义的 ENR 构建,ENR 是其核心基础。 |
| ENR 交换机制 | 获取最新 ENR 通常需要发送一个特定的 ENRRequest 请求。 | ENR 直接包含在常规的消息中(如 FINDNODE 的 NODES 响应),无需特定请求。 |
| ENR 内容与功能利用 | 主要用于提供更丰富的节点元数据和改进的端点证明。 | 充分利用 ENR 的键值对灵活性,支持如**主题宣告(Topic Advertisement)**等高级功能,允许节点声明特定服务或协议,实现更精确的节点发现。 |
| 身份方案 | ENR 使用 “v4” 身份方案。(此处的 v4 为身份方法的名称,而非上文的 discv4) | 依赖 EIP-778 定义的身份方案,具有更好的扩展性(尽管 “v4” 仍常用)。 |
DNS 发现(DNS Discovery) 该机制作为基于 UDP 的 P2P 发现协议(Discv4/Discv5)的补充,旨在提供一个稳定且易于更新的节点列表(特别是引导节点)作为客户端连接网络的初始入口点。文档详细说明了如何将以太坊节点信息(通常是以太坊节点记录 ENR)编码成特定的字符串格式,并存储在 DNS 记录(通常是 TXT 记录)中。这些 DNS 域名和记录由可信的列表维护者管理和发布。客户端通过查询这些特定的 DNS 域名来获取 ENR 列表,然后可以使用列表中的节点启动 Discv5 或 Discv4 p2p 发现流程。