Mirrored from scikit-multilearn/scikit-multilearn#289
Hello I've successfully forked the scikit-multilearn repo, branched off of master, and completed this issue but I was unable to make a pull request. Could I please be given write access or someone with write access can implement my solution.
The iterative_train_test_split function does not have a shuffle parameter and therefore does not shuffle the data ahead of time. I understand that the underlying IterativeStratification object does have a shuffle property which is set to True if a random_state is provided. But that doesn't shuffle because the underlying _iter_test_indices doesn't perform shuffling unlike the sibling class KFold which extends the same _BaseKFold parent class. The consequences of this are that when calling iterative_train_test_split across several cross-fold iterations, the instance-inclusion is not remotely normally distributed. Using an example dataset with ground truth including 12 labels (and about 6,000 instances), here's a plot of the instance-inclusion for the test set (20%test_size) distribution across 100 CV iterations:

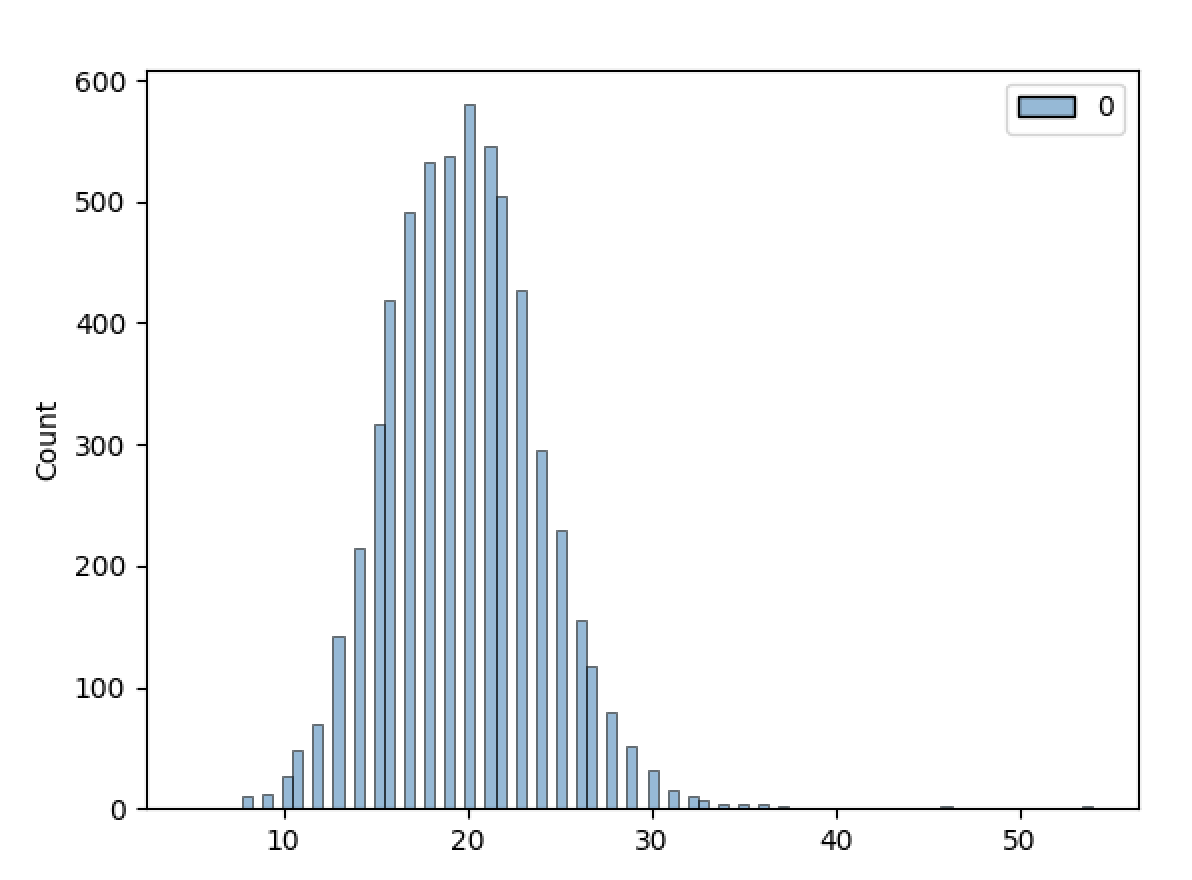
What this plot means is that across the CV iterations, there were several of the test set instances that were included every iteration (all 100 of them). This means that the CV folds were not balanced enough because several of the instances were included every single time and the other instances hardly at all. This means that when splitting the test dataset, we're mostly testing on the same instances over and over again rather than getting a balance of different instances in each fold. The converse being that we're also training on the same instances over and over again rather than training on a balance of the instances from the complete dataset. After shuffling using my solution, the instance-inclusion distribution is much more normal:
My solution additionally makes the deviation of label proportions in each fold from the original label proportions much smaller, improving the performance of the iterative stratification. Without shuffling, the test set proportions deviated by less than 5%
"Label 1": 3.9850468575761893,
"Label 2": 4.194394462998466,
"Label 3": 4.462827268806928,
"Label 4": 4.098111373194331,
"Label 5": 3.7208254441759623,
...
But after shuffling the test set proportions deviated by less than 3%
"Label 1": 2.1211386224760536,
"Label 2": 2.0732622302730945,
"Label 3": 2.0317471358023833,
"Label 4": 2.8221312795976012,
"Label 5": 2.370255420932089,
...
Here's my solution. Again I could just make a pull request since I already have the solution implemented but I need write access to this repo.
Change the function signature from this:
def iterative_train_test_split(X, y, test_size, random_state=None):
to this:
def iterative_train_test_split(X, y, test_size, random_state=None, shuffle=False):
Add a docstring description for the new parameter:
shuffle : bool
Whether to shuffle the data before splitting into batches. Note that the samples within each split
will not be shuffled.
Add this code to the function before calling next:
if shuffle:
indices = list(y.index)
check_random_state(random_state).shuffle(indices)
X = X.loc[indices]
y = y.loc[indices]
Hello I've successfully forked the
scikit-multilearnrepo, branched off of master, and completed this issue but I was unable to make a pull request. Could I please be given write access or someone with write access can implement my solution.The


iterative_train_test_splitfunction does not have a shuffle parameter and therefore does not shuffle the data ahead of time. I understand that the underlyingIterativeStratificationobject does have ashuffleproperty which is set toTrueif arandom_stateis provided. But that doesn't shuffle because the underlying_iter_test_indicesdoesn't perform shuffling unlike the sibling classKFoldwhich extends the same_BaseKFoldparent class. The consequences of this are that when callingiterative_train_test_splitacross several cross-fold iterations, the instance-inclusion is not remotely normally distributed. Using an example dataset with ground truth including 12 labels (and about 6,000 instances), here's a plot of the instance-inclusion for the test set (20%test_size) distribution across 100 CV iterations:What this plot means is that across the CV iterations, there were several of the test set instances that were included every iteration (all 100 of them). This means that the CV folds were not balanced enough because several of the instances were included every single time and the other instances hardly at all. This means that when splitting the test dataset, we're mostly testing on the same instances over and over again rather than getting a balance of different instances in each fold. The converse being that we're also training on the same instances over and over again rather than training on a balance of the instances from the complete dataset. After shuffling using my solution, the instance-inclusion distribution is much more normal:
My solution additionally makes the deviation of label proportions in each fold from the original label proportions much smaller, improving the performance of the iterative stratification. Without shuffling, the test set proportions deviated by less than 5%
But after shuffling the test set proportions deviated by less than 3%
Here's my solution. Again I could just make a pull request since I already have the solution implemented but I need write access to this repo.
Change the function signature from this:
to this:
Add a docstring description for the new parameter:
Add this code to the function before calling
next: