diff --git a/.gitignore b/.gitignore
index a1d21056b..eb5ff0074 100644
--- a/.gitignore
+++ b/.gitignore
@@ -82,3 +82,4 @@ nbs/
__pycache__/
.cache/
+**/.ipynb_checkpoints/
diff --git a/chapters/te/_toctree.yml b/chapters/te/_toctree.yml
index 301decc44..001b1d11c 100644
--- a/chapters/te/_toctree.yml
+++ b/chapters/te/_toctree.yml
@@ -26,4 +26,24 @@
title: సారాంశం
- local: chapter1/11
title: పరీక్ష
- quiz: 1
\ No newline at end of file
+ quiz: 1
+- title: 2. ట్రాన్స్ఫార్మర్లు ఉపయోగించడం
+ sections:
+ - local: chapter2/1
+ title: పరిచయం
+ - local: chapter2/2
+ title: పైప్లైన్ వెనుక
+ - local: chapter2/3
+ title: మోడల్స్
+ - local: chapter2/4
+ title: టోకనైజర్లు
+ - local: chapter2/5
+ title: బహుళ సీక్వెన్సుల నిర్వహణ
+ - local: chapter2/6
+ title: అన్నింటినీ కలిపి
+ - local: chapter2/7
+ title: ప్రాథమిక వినియోగం పూర్తయింది!
+ - local: chapter2/8
+ title: ఆప్టిమైజ్డ్ ఇన్ఫరెన్స్ డిప్లాయ్మెంట్
+ - local: chapter2/9
+ title: అధ్యాయం ముగింపు క్విజ్
\ No newline at end of file
diff --git a/chapters/te/chapter2/1.mdx b/chapters/te/chapter2/1.mdx
new file mode 100644
index 000000000..6beddd7b3
--- /dev/null
+++ b/chapters/te/chapter2/1.mdx
@@ -0,0 +1,24 @@
+# పరిచయం
+
+
+
+మీరు [అధ్యాయం 1](/course/chapter1) లో చూసినట్లుగా, Transformer మోడళ్లు సాధారణంగా చాలా పెద్దవిగా ఉంటాయి. లక్షల నుండి *బిలియన్ల* వరకు పరామితులు ఉండటం వల్ల, ఈ మోడళ్లను శిక్షణ ఇవ్వడం మరియు అమలు చేయడం ఒక క్లిష్టమైన పని. అంతేకాకుండా, కొత్త మోడళ్లు దాదాపు ప్రతిరోజూ విడుదల అవుతుండటంతో మరియు ప్రతి మోడల్కు స్వంత అమలు ఉండటంతో, వాటిని అన్నింటినీ ప్రయత్నించడం అంత తేలిక కాదు.
+
+ఈ సమస్యను పరిష్కరించడానికి 🤗 Transformers లైబ్రరీ రూపొందించబడింది. దీని లక్ష్యం ఏ Transformer మోడల్నైనా ఒకే API ద్వారా లోడ్ చేయడం, శిక్షణ ఇవ్వడం, మరియు భద్రపరచడం సాధ్యమయ్యేలా చేయడం. ఈ లైబ్రరీ యొక్క ముఖ్య లక్షణాలు ఇవి:
+
+- **వాడుకలో సులభత**: అత్యాధునిక NLP మోడల్ను inference కోసం download చేసి, లోడ్ చేసి, ఉపయోగించడం కేవలం రెండు పంక్తుల కోడ్తో చేయవచ్చు.
+- **అనుకూలత**: లోతుగా చూస్తే అన్ని మోడళ్లు సాధారణ PyTorch `nn.Module` తరగతులు మాత్రమే, కాబట్టి వాటిని వారి ML frameworkలలోని ఇతర మోడళ్లలాగే ఉపయోగించవచ్చు.
+- **సరళత**: లైబ్రరీ అంతటా తక్కువ abstractions మాత్రమే ఉన్నాయి. "అన్నీ ఒకే ఫైల్లో" అనే భావన ఇక్కడ ప్రధానమైనది: ఒక మోడల్ యొక్క forward pass మొత్తం ఒకే ఫైల్లో నిర్వచించబడుతుంది, కాబట్టి కోడ్ సులభంగా అర్థమవుతుంది మరియు మార్చుకోవచ్చు.
+
+ఈ చివరి లక్షణం 🤗 Transformers ను ఇతర ML లైబ్రరీలతో పోలిస్తే కొంచెం భిన్నంగా ఉంచుతుంది. మోడళ్లు వేర్వేరు ఫైళ్లలో పంచుకున్న modules ఆధారంగా కాకుండా, ప్రతి మోడల్ తనకంటూ ప్రత్యేకమైన పొరలను (layers) కలిగి ఉంటుంది. దీని వలన మోడళ్లు మరింత సులభంగా అర్థమవుతాయి, అలాగే ఒక మోడల్పై ప్రయోగాలు చేయడం వలన ఇతర మోడళ్లపై ప్రభావం ఉండదు.
+
+ఈ అధ్యాయం ఒక end-to-end ఉదాహరణతో ప్రారంభమవుతుంది, ఇందులో మనం ఒక model మరియు tokenizer ను కలిపి [అధ్యాయం 1](/course/chapter1) లో పరిచయం చేసిన `pipeline()` function ను పునరావృతం చేస్తాము. తర్వాత మనం model API గురించి చర్చిస్తాము: model మరియు configuration classes లోకి వెళ్లి, ఒక మోడల్ను ఎలా లోడ్ చేయాలో, అది సంఖ్యా inputs ను తీసుకుని ఎలా ఫలితాలను ఇస్తుందో చూస్తాము.
+
+తర్వాత మనం tokenizer API ను పరిశీలిస్తాము, ఇది `pipeline()` function యొక్క మరో ముఖ్యమైన భాగం. Tokenizers మొదటి మరియు చివరి ప్రాసెసింగ్ దశలను చూసుకుంటాయి: text ను సంఖ్యా inputs గా మార్చడం, మరియు అవసరమైనప్పుడు ఫలితాలను తిరిగి text లోకి మార్చడం. చివరగా, ఒకే batch లోకి అనేక వాక్యాలను పంపడం ఎలా చేయాలో, మరియు high-level `tokenizer()` function ను దగ్గరగా పరిశీలిస్తాము.
+
+
+⚠️ Model Hub మరియు 🤗 Transformers లో అందుబాటులో ఉన్న అన్ని ఫీచర్లను ఉపయోగించుకోవాలంటే, మేము ఒక ఖాతా సృష్టించుకోవాలని సిఫారసు చేస్తున్నాము.
+
diff --git a/chapters/te/chapter2/2.mdx b/chapters/te/chapter2/2.mdx
new file mode 100644
index 000000000..b871ada22
--- /dev/null
+++ b/chapters/te/chapter2/2.mdx
@@ -0,0 +1,239 @@
+
+
+# పైప్లైన్ వెనుక
+
+
+
+
+
+ఇప్పుడు ఒక పూర్తి ఉదాహరణతో ప్రారంభిద్దాం. [అధ్యాయం 1](/course/chapter1)లో మనం క్రింది కోడ్ను నడిపినప్పుడు వెనుకపట్లో ఏమి జరిగిందో చూద్దాం:
+
+```python
+from transformers import pipeline
+
+classifier = pipeline("sentiment-analysis")
+classifier(
+ [
+ "I've been waiting for a HuggingFace course my whole life.",
+ "I hate this so much!",
+ ]
+)
+```
+
+మరియు మనకు వచ్చిన ఫలితాలు:
+
+```python out
+[{'label': 'POSITIVE', 'score': 0.9598047137260437},
+ {'label': 'NEGATIVE', 'score': 0.9994558095932007}]
+```
+
+[అధ్యాయం 1](/course/chapter1)లో చూశినట్లుగా, ఈ పైప్లైన్ మూడు దశలను కలిపి అమలు చేస్తుంది: ప్రీప్రాసెసింగ్, ఇన్పుట్లను మోడల్ ద్వారా పంపించడం, మరియు పోస్ట్ప్రాసెసింగ్:
+
+
+

+

+
+

+

+
+

+

+
+

+

+
+

+

+
 +
+
+
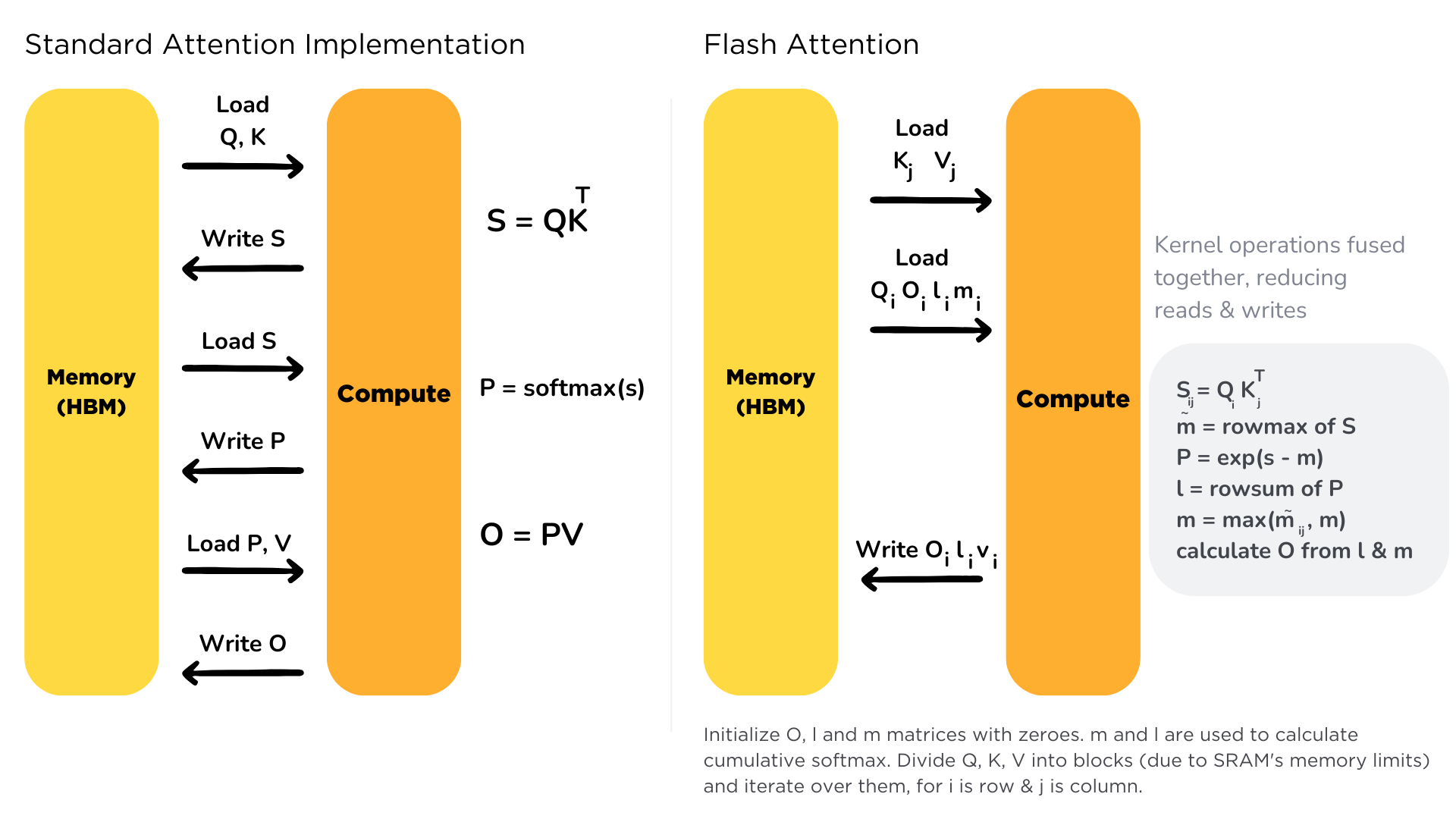
+Flash Attention అనేది transformer models లోని attention mechanism ను ఆప్టిమైజ్ చేయడానికి ఉపయోగించే సాంకేతికత.
+మనం [అధ్యాయం 1.8](/course/chapter1/8) లో చర్చించినట్టుగా, attention కి quadratic complexity ఉండటం వలన, దీని computation మరియు memory వినియోగం ఎక్కువగా ఉంటుంది.
+
+Flash Attention యొక్క ప్రధాన ఆవిష్కరణ HBM (High Bandwidth Memory) మరియు SRAM cache మధ్య memory transfer ను తగ్గించడంలో ఉంది. సాధారణ attention లో ఈ transfers చాలా సార్లు జరుగుతూ bottleneck అవుతాయి.
+Flash Attention డేటాను ఒక్కసారి SRAM లోకి లోడ్ చేసి, calculations అంతా అక్కడే పూర్తి చేస్తుంది, దాంతో memory overhead చాలా తగ్గుతుంది.
+
+ఈ ప్రయోజనాలు training సమయంలో ఎక్కువగా కనిపించినా, inference సమయంలో కూడా VRAM వినియోగం తగ్గడం మరియు వేగం పెరగడం వంటి ప్రయోజనాలు అందిస్తుంది.
+
+
+
+**vLLM** పూర్తిగా వేరు విధానాన్ని అనుసరిస్తుంది — దీని ప్రత్యేకత *PagedAttention*.
+ఇది కంప్యూటర్ virtual memory లానే పనిచేస్తుంది: మోడల్ memory ను చిన్న చిన్న “pages” గా విభజిస్తుంది. దీని ద్వారా requests వేర్వేరు sizes అయినా memory ని వృథా చేయకుండా హ్యాండిల్ చేయవచ్చు.
+ఇది memory fragmentation ను తగ్గిస్తూ, KV cache ను సమర్థవంతంగా నిర్వహిస్తుంది, తద్వారా throughput భారీగా పెరుగుతుంది.
+
+
+
+PagedAttention, KV cache నిర్వహణలో ఉండే bottlenecks ను పరిష్కరించడానికి రూపొందించబడింది.
+LLM generation సమయంలో, ప్రతి token కి keys మరియు values (KV cache) నిల్వ చేయాలి. దీని memory చాలా పెద్దది అవుతుంది — ముఖ్యంగా long sequences లేదా concurrent requests వద్ద.
+
+vLLM యొక్క కీలక ఆవిష్కరణలు ఇవి:
+
+1. **Memory Paging** – KV cache ను పెద్ద continuous block లాగా కాకుండా చిన్న pages గా విభజించడం
+2. **Non-contiguous Storage** – GPU memory లో pages continuous గా ఉండాల్సిన అవసరం లేదు
+3. **Page Table** – ఏ pages ఏ sequence కు చెందినవి అనే సమాచారం నిర్వహించడం
+4. **Memory Sharing** – ఒక prompt కి సంబంధించిన KV cache pages ని అనేక sequences మధ్య share చేయడం
+
+ఈ పద్ధతి సంప్రదాయ inference పద్ధతుల కంటే *24x వరకు* ఎక్కువ throughput అందించగలదు.
+వివరంగా తెలుసుకోవాలంటే, [vLLM documentation](https://docs.vllm.ai/en/latest/design/kernel/paged_attention.html) చదవవచ్చు.
+
+
+
+**llama.cpp** అనేది అత్యంత ఆప్టిమైజ్ చేయబడిన C/C++ implementation. మొదట ఇది consumer hardware పై LLaMA మోడళ్లను రన్ చేయడానికి రూపొందించబడింది.
+ఇది CPU పై అత్యంత సమర్థవంతంగా పనిచేస్తుంది, అవసరమైతే GPU acceleration కూడా అందిస్తుంది.
+llama.cpp మోడల్ ను quantize చేసి చిన్న పరిమాణంలోకి మార్చుతుంది — అలా VRAM వినియోగం తగ్గి inference వేగం పెరుగుతుంది.
+
+
+
+Quantization అనేది మోడల్ weights ను FP32/FP16 నుండి తక్కువ precision (INT8, 4-bit మొదలైనవి) కు మార్చే ప్రక్రియ.
+ఇది memory వినియోగాన్ని గణనీయంగా తగ్గించి inference వేగాన్ని పెంచుతుంది., accuracy లో తక్కువ నష్టం మాత్రమే ఉంటుంది.
+
+llama.cpp లోని ముఖ్యమైన quantization ప్రయోజనాలు:
+
+1. **అనేక precision స్థాయిలు** – INT8, 4-bit, 3-bit, 2-bit వరకు
+2. **GGML/GGUF ఫార్మాట్లు** – quantized inference కోసం ఆప్టిమైజ్ చేసిన టెన్సర్ ఫార్మాట్లు
+3. **Mixed precision** – మోడల్లో వేర్వేరు భాగాలకు వేర్వేరు quantization స్థాయిలు
+4. **CPU optimizations** – AVX2, AVX-512, NEON వంటి CPU నిర్మాణాల (architectures) కోసం ఆప్టిమైజ్ చేసిన kernels
+
+ఈ విధానం, తక్కువ memory ఉన్న consumer devices పై కూడా పెద్ద మోడళ్లను రన్ చేయడానికి మార్గాన్ని అందిస్తుంది.
+
+
+
+### Deployment మరియు Integration
+
+ఇప్పుడు frameworks deployment మరియు integration పరంగా ఎలా భిన్నంగా ఉన్నాయో చూద్దాం.
+
+**TGI** enterprise-స్థాయి deployment లో అత్యుత్తమం.
+ఇది production కి అవసరమైన వాటిని built-in గా అందిస్తుంది — Kubernetes support, monitoring (Prometheus/Grafana), autoscaling, content filtering, rate limiting, security features మొదలైనవి.
+అంతేకాకుండా enterprise-grade logging కూడా కలిగి ఉంది.
+
+**vLLM** flexible మరియు developer-friendly గా రూపొందించబడింది.
+ఇది Python ఆధారంగా పనిచేస్తుంది మరియు మీ existing applications లో OpenAI API స్థానంలో సులభంగా plug చేయవచ్చు.
+Clusters నిర్వహణ కోసం Ray తో బాగా పని చేస్తుంది.
+
+**llama.cpp** సాదాసీదా, తేలికైన server implementation కలిగి ఉంది.
+Python frameworks ను install చేయడం కష్టమైన పరిసరాల్లో కూడా deployment సులభం.
+ఇది OpenAI-compatible API కూడా అందిస్తుంది, కానీ resource వినియోగం చాలా తక్కువ.
+
+## ప్రారంభించడం
+
+ఇప్పుడు ఈ frameworks ను ఎలా ఉపయోగించాలో — సంస్థాపన (installation) నుండి deployment వరకూ — చూద్దాం.
+
+### సంస్థాపన మరియు ప్రాథమిక సెటప్
+
+
+
+
+
+TGI ను Hugging Face ecosystem తో బాగా integrate చేశారు, మరియు సంస్థాపన చాలా సులభం.
+
+మొదట, Docker తో TGI server ను ప్రారంభించండి:
+
+```sh
+docker run --gpus all \
+ --shm-size 1g \
+ -p 8080:80 \
+ -v ~/.cache/huggingface:/data \
+ ghcr.io/huggingface/text-generation-inference:latest \
+ --model-id HuggingFaceTB/SmolLM2-360M-Instruct
+```
+
+తరువాత Hugging Face InferenceClient తో ఇంటరాక్ట్ అవండి:
+
+```python
+from huggingface_hub import InferenceClient
+
+# Initialize client pointing to TGI endpoint
+client = InferenceClient(
+ model="http://localhost:8080", # URL to the TGI server
+)
+
+# Text generation
+response = client.text_generation(
+ "Tell me a story",
+ max_new_tokens=100,
+ temperature=0.7,
+ top_p=0.95,
+ details=True,
+ stop_sequences=[],
+)
+print(response.generated_text)
+
+# For chat format
+response = client.chat_completion(
+ messages=[
+ {"role": "system", "content": "You are a helpful assistant."},
+ {"role": "user", "content": "Tell me a story"},
+ ],
+ max_tokens=100,
+ temperature=0.7,
+ top_p=0.95,
+)
+print(response.choices[0].message.content)
+```
+
+లేదా OpenAI client ఉపయోగించవచ్చు:
+
+```python
+from openai import OpenAI
+
+# Initialize client pointing to TGI endpoint
+client = OpenAI(
+ base_url="http://localhost:8080/v1", # Make sure to include /v1
+ api_key="not-needed", # TGI doesn't require an API key by default
+)
+
+# Chat completion
+response = client.chat.completions.create(
+ model="HuggingFaceTB/SmolLM2-360M-Instruct",
+ messages=[
+ {"role": "system", "content": "You are a helpful assistant."},
+ {"role": "user", "content": "Tell me a story"},
+ ],
+ max_tokens=100,
+ temperature=0.7,
+ top_p=0.95,
+)
+print(response.choices[0].message.content)
+```
+
+
+
+
+
+llama.cpp సంస్థాపన చాలా తేలికగా ఉంటుంది; CPU మరియు GPU inference రెండింటిని సపోర్ట్ చేస్తుంది.
+
+మొదట, llama.cpp ని build చేయండి:
+
+```sh
+# Clone the repository
+git clone https://github.com/ggerganov/llama.cpp
+cd llama.cpp
+
+# Build the project
+make
+
+# Download the SmolLM2-1.7B-Instruct-GGUF model
+curl -L -O https://huggingface.co/HuggingFaceTB/SmolLM2-1.7B-Instruct-GGUF/resolve/main/smollm2-1.7b-instruct.Q4_K_M.gguf
+```
+
+OpenAI-compatible server ను ప్రారంభించండి:
+
+```sh
+# Start the server
+./server \
+ -m smollm2-1.7b-instruct.Q4_K_M.gguf \
+ --host 0.0.0.0 \
+ --port 8080 \
+ -c 4096 \
+ --n-gpu-layers 0 # Set to a higher number to use GPU
+```
+
+InferenceClient తో interact చేయండి:
+
+```python
+from huggingface_hub import InferenceClient
+
+# Initialize client pointing to llama.cpp server
+client = InferenceClient(
+ model="http://localhost:8080/v1", # URL to the llama.cpp server
+ token="sk-no-key-required", # llama.cpp server requires this placeholder
+)
+
+# Text generation
+response = client.text_generation(
+ "Tell me a story",
+ max_new_tokens=100,
+ temperature=0.7,
+ top_p=0.95,
+ details=True,
+)
+print(response.generated_text)
+
+# For chat format
+response = client.chat_completion(
+ messages=[
+ {"role": "system", "content": "You are a helpful assistant."},
+ {"role": "user", "content": "Tell me a story"},
+ ],
+ max_tokens=100,
+ temperature=0.7,
+ top_p=0.95,
+)
+print(response.choices[0].message.content)
+```
+
+లేదా OpenAI client ఉపయోగించండి:
+
+```python
+from openai import OpenAI
+
+# Initialize client pointing to llama.cpp server
+client = OpenAI(
+ base_url="http://localhost:8080/v1",
+ api_key="sk-no-key-required", # llama.cpp server requires this placeholder
+)
+
+# Chat completion
+response = client.chat.completions.create(
+ model="smollm2-1.7b-instruct", # Model identifier can be anything as server only loads one model
+ messages=[
+ {"role": "system", "content": "You are a helpful assistant."},
+ {"role": "user", "content": "Tell me a story"},
+ ],
+ max_tokens=100,
+ temperature=0.7,
+ top_p=0.95,
+)
+print(response.choices[0].message.content)
+```
+
+
+
+
+
+vLLM సంస్థాపన కూడా అత్యంత సులభం. ఇది OpenAI-compatible API మరియు native Python interface రెండింటినీ అందిస్తుంది.
+
+మొదట, vLLM server ను ప్రారంభించండి:
+
+```sh
+python -m vllm.entrypoints.openai.api_server \
+ --model HuggingFaceTB/SmolLM2-360M-Instruct \
+ --host 0.0.0.0 \
+ --port 8000
+```
+
+InferenceClient తో ఉపయోగించండి:
+
+```python
+from huggingface_hub import InferenceClient
+
+# Initialize client pointing to vLLM endpoint
+client = InferenceClient(
+ model="http://localhost:8000/v1", # URL to the vLLM server
+)
+
+# Text generation
+response = client.text_generation(
+ "Tell me a story",
+ max_new_tokens=100,
+ temperature=0.7,
+ top_p=0.95,
+ details=True,
+)
+print(response.generated_text)
+
+# For chat format
+response = client.chat_completion(
+ messages=[
+ {"role": "system", "content": "You are a helpful assistant."},
+ {"role": "user", "content": "Tell me a story"},
+ ],
+ max_tokens=100,
+ temperature=0.7,
+ top_p=0.95,
+)
+print(response.choices[0].message.content)
+```
+
+లేదా OpenAI client:
+
+```python
+from openai import OpenAI
+
+# Initialize client pointing to vLLM endpoint
+client = OpenAI(
+ base_url="http://localhost:8000/v1",
+ api_key="not-needed", # vLLM doesn't require an API key by default
+)
+
+# Chat completion
+response = client.chat.completions.create(
+ model="HuggingFaceTB/SmolLM2-360M-Instruct",
+ messages=[
+ {"role": "system", "content": "You are a helpful assistant."},
+ {"role": "user", "content": "Tell me a story"},
+ ],
+ max_tokens=100,
+ temperature=0.7,
+ top_p=0.95,
+)
+print(response.choices[0].message.content)
+```
+
+
+
+
+
+### ప్రాథమిక టెక్స్ట్ జనరేషన్
+
+ఇప్పుడు frameworks లో text generation ఎలా చేయాలో చూద్దాం.
+
+
+
+
+
+మొదట, అభివృద్ధి చెందిన parameters తో TGI deploy చేయండి:
+
+```sh
+docker run --gpus all \
+ --shm-size 1g \
+ -p 8080:80 \
+ -v ~/.cache/huggingface:/data \
+ ghcr.io/huggingface/text-generation-inference:latest \
+ --model-id HuggingFaceTB/SmolLM2-360M-Instruct \
+ --max-total-tokens 4096 \
+ --max-input-length 3072 \
+ --max-batch-total-tokens 8192 \
+ --waiting-served-ratio 1.2
+```
+
+InferenceClient తో generation చేయండి:
+
+```python
+from huggingface_hub import InferenceClient
+
+client = InferenceClient(model="http://localhost:8080")
+
+# Advanced parameters example
+response = client.chat_completion(
+ messages=[
+ {"role": "system", "content": "You are a creative storyteller."},
+ {"role": "user", "content": "Write a creative story"},
+ ],
+ temperature=0.8,
+ max_tokens=200,
+ top_p=0.95,
+)
+print(response.choices[0].message.content)
+
+# Raw text generation
+response = client.text_generation(
+ "Write a creative story about space exploration",
+ max_new_tokens=200,
+ temperature=0.8,
+ top_p=0.95,
+ repetition_penalty=1.1,
+ do_sample=True,
+ details=True,
+)
+print(response.generated_text)
+```
+
+లేదా OpenAI client:
+```python
+from openai import OpenAI
+
+client = OpenAI(base_url="http://localhost:8080/v1", api_key="not-needed")
+
+# Advanced parameters example
+response = client.chat.completions.create(
+ model="HuggingFaceTB/SmolLM2-360M-Instruct",
+ messages=[
+ {"role": "system", "content": "You are a creative storyteller."},
+ {"role": "user", "content": "Write a creative story"},
+ ],
+ temperature=0.8, # Higher for more creativity
+)
+print(response.choices[0].message.content)
+```
+
+
+
+
+
+llama.cpp లో server launch సమయంలో advanced parameters సెట్ చేయవచ్చు:
+
+```sh
+./server \
+ -m smollm2-1.7b-instruct.Q4_K_M.gguf \
+ --host 0.0.0.0 \
+ --port 8080 \
+ -c 4096 \ # Context size
+ --threads 8 \ # CPU threads to use
+ --batch-size 512 \ # Batch size for prompt evaluation
+ --n-gpu-layers 0 # GPU layers (0 = CPU only)
+```
+
+InferenceClient తో ఉపయోగించండి:
+
+```python
+from huggingface_hub import InferenceClient
+
+client = InferenceClient(model="http://localhost:8080/v1", token="sk-no-key-required")
+
+# Advanced parameters example
+response = client.chat_completion(
+ messages=[
+ {"role": "system", "content": "You are a creative storyteller."},
+ {"role": "user", "content": "Write a creative story"},
+ ],
+ temperature=0.8,
+ max_tokens=200,
+ top_p=0.95,
+)
+print(response.choices[0].message.content)
+
+# For direct text generation
+response = client.text_generation(
+ "Write a creative story about space exploration",
+ max_new_tokens=200,
+ temperature=0.8,
+ top_p=0.95,
+ repetition_penalty=1.1,
+ details=True,
+)
+print(response.generated_text)
+```
+
+లేదా నమూనా పారామితులపై నియంత్రణతో జనరేషన్ కోసం OpenAI క్లయింట్ని ఉపయోగించండి:
+
+```python
+from openai import OpenAI
+
+client = OpenAI(base_url="http://localhost:8080/v1", api_key="sk-no-key-required")
+
+# Advanced parameters example
+response = client.chat.completions.create(
+ model="smollm2-1.7b-instruct",
+ messages=[
+ {"role": "system", "content": "You are a creative storyteller."},
+ {"role": "user", "content": "Write a creative story"},
+ ],
+ temperature=0.8, # Higher for more creativity
+ top_p=0.95, # Nucleus sampling probability
+ frequency_penalty=0.5, # Reduce repetition of frequent tokens
+ presence_penalty=0.5, # Reduce repetition by penalizing tokens already present
+ max_tokens=200, # Maximum generation length
+)
+print(response.choices[0].message.content)
+```
+
+అదనంగా, llama.cpp native library తో మరింత నియంత్రణ పొందవచ్చు:
+
+```python
+# Using llama-cpp-python package for direct model access
+from llama_cpp import Llama
+
+# Load the model
+llm = Llama(
+ model_path="smollm2-1.7b-instruct.Q4_K_M.gguf",
+ n_ctx=4096, # Context window size
+ n_threads=8, # CPU threads
+ n_gpu_layers=0, # GPU layers (0 = CPU only)
+)
+
+# Format prompt according to the model's expected format
+prompt = """<|im_start|>system
+You are a creative storyteller.
+<|im_end|>
+<|im_start|>user
+Write a creative story
+<|im_end|>
+<|im_start|>assistant
+"""
+
+# Generate response with precise parameter control
+output = llm(
+ prompt,
+ max_tokens=200,
+ temperature=0.8,
+ top_p=0.95,
+ frequency_penalty=0.5,
+ presence_penalty=0.5,
+ stop=["<|im_end|>"],
+)
+
+print(output["choices"][0]["text"])
+```
+
+
+
+
+
+vLLM తో అధునాతన ఉపయోగం కోసం, మీరు InferenceClient ని ఉపయోగించవచ్చు:
+
+```python
+from huggingface_hub import InferenceClient
+
+client = InferenceClient(model="http://localhost:8000/v1")
+
+# Advanced parameters example
+response = client.chat_completion(
+ messages=[
+ {"role": "system", "content": "You are a creative storyteller."},
+ {"role": "user", "content": "Write a creative story"},
+ ],
+ temperature=0.8,
+ max_tokens=200,
+ top_p=0.95,
+)
+print(response.choices[0].message.content)
+
+# For direct text generation
+response = client.text_generation(
+ "Write a creative story about space exploration",
+ max_new_tokens=200,
+ temperature=0.8,
+ top_p=0.95,
+ details=True,
+)
+print(response.generated_text)
+```
+
+మీరు OpenAI client కూడా ఉపయోగించవచ్చు:
+
+```python
+from openai import OpenAI
+
+client = OpenAI(base_url="http://localhost:8000/v1", api_key="not-needed")
+
+# Advanced parameters example
+response = client.chat.completions.create(
+ model="HuggingFaceTB/SmolLM2-360M-Instruct",
+ messages=[
+ {"role": "system", "content": "You are a creative storyteller."},
+ {"role": "user", "content": "Write a creative story"},
+ ],
+ temperature=0.8,
+ top_p=0.95,
+ max_tokens=200,
+)
+print(response.choices[0].message.content)
+```
+
+vLLM లో స్థానిక పైథాన్ interface కూడా ఉంది:
+
+```python
+from vllm import LLM, SamplingParams
+
+# Initialize the model with advanced parameters
+llm = LLM(
+ model="HuggingFaceTB/SmolLM2-360M-Instruct",
+ gpu_memory_utilization=0.85,
+ max_num_batched_tokens=8192,
+ max_num_seqs=256,
+ block_size=16,
+)
+
+# Configure sampling parameters
+sampling_params = SamplingParams(
+ temperature=0.8, # Higher for more creativity
+ top_p=0.95, # Consider top 95% probability mass
+ max_tokens=100, # Maximum length
+ presence_penalty=1.1, # Reduce repetition
+ frequency_penalty=1.1, # Reduce repetition
+ stop=["\n\n", "###"], # Stop sequences
+)
+
+# Generate text
+prompt = "Write a creative story"
+outputs = llm.generate(prompt, sampling_params)
+print(outputs[0].outputs[0].text)
+
+# For chat-style interactions
+chat_prompt = [
+ {"role": "system", "content": "You are a creative storyteller."},
+ {"role": "user", "content": "Write a creative story"},
+]
+formatted_prompt = llm.get_chat_template()(chat_prompt) # Uses model's chat template
+outputs = llm.generate(formatted_prompt, sampling_params)
+print(outputs[0].outputs[0].text)
+```
+
+
+
+
+
+## అధునాతన జనరేషన్ నియంత్రణ
+
+### Token ఎంపిక మరియు Sampling
+
+టెక్స్ట్ను జనరేట్ చేసే ప్రక్రియలో, ప్రతి దశలో వచ్చే తదుపరి token ను ఎంపిక చేయాలి. ఈ ఎంపికను పలు నియంత్రణ పరామితుల ద్వారా ప్రభావితం చేయవచ్చు:
+
+1. **Raw Logits**: ప్రతి token కోసం మోడల్ ఇచ్చే ప్రారంభ probability విలువలు
+2. **Temperature**: యాదృచ్ఛికతను నియంత్రిస్తుంది (విలువ ఎక్కువైతే output మరింత creative గా ఉంటుంది)
+3. **Top-p (Nucleus) Sampling**: మొత్తం probability లో X% వచ్చే వరకు ఉన్న అత్యుత్తమ tokens ను మాత్రమే పరిగణలోకి తీసుకోవడం
+4. **Top-k Filtering**: అత్యంత సాధ్యమైన k tokens కు selection ను పరిమితం చేయడం
+
+ఈ పరామితులను ఎలా సెట్ చేయాలో ఇక్కడ చూపుతున్నాం:
+
+
+
+
+
+```python
+client.generate(
+ "Write a creative story",
+ temperature=0.8, # Higher for more creativity
+ top_p=0.95, # Consider top 95% probability mass
+ top_k=50, # Consider top 50 tokens
+ max_new_tokens=100, # Maximum length
+ repetition_penalty=1.1, # Reduce repetition
+)
+```
+
+
+
+
+
+```python
+# Via OpenAI API compatibility
+response = client.completions.create(
+ model="smollm2-1.7b-instruct", # Model name (can be any string for llama.cpp server)
+ prompt="Write a creative story",
+ temperature=0.8, # Higher for more creativity
+ top_p=0.95, # Consider top 95% probability mass
+ frequency_penalty=1.1, # Reduce repetition
+ presence_penalty=0.1, # Reduce repetition
+ max_tokens=100, # Maximum length
+)
+
+# Via llama-cpp-python direct access
+output = llm(
+ "Write a creative story",
+ temperature=0.8,
+ top_p=0.95,
+ top_k=50,
+ max_tokens=100,
+ repeat_penalty=1.1,
+)
+```
+
+
+
+
+
+```python
+params = SamplingParams(
+ temperature=0.8, # Higher for more creativity
+ top_p=0.95, # Consider top 95% probability mass
+ top_k=50, # Consider top 50 tokens
+ max_tokens=100, # Maximum length
+ presence_penalty=0.1, # Reduce repetition
+)
+llm.generate("Write a creative story", sampling_params=params)
+```
+
+
+
+
+
+### పునరావృతం నివారణ (Controlling Repetition)
+
+పునరావృతమైన లేదా ఒకే విధమైన టెక్స్ట్ను మోడల్ నిరంతరం ఉత్పత్తి చేయకుండా నిలువరించడానికి frameworks నియంత్రణ పద్ధతులు అందిస్తాయి:
+
+
+
+
+
+```python
+client.generate(
+ "Write a varied text",
+ repetition_penalty=1.1, # Penalize repeated tokens
+ no_repeat_ngram_size=3, # Prevent 3-gram repetition
+)
+```
+
+
+
+
+
+```python
+# Via OpenAI API
+response = client.completions.create(
+ model="smollm2-1.7b-instruct",
+ prompt="Write a varied text",
+ frequency_penalty=1.1, # Penalize frequent tokens
+ presence_penalty=0.8, # Penalize tokens already present
+)
+
+# Via direct library
+output = llm(
+ "Write a varied text",
+ repeat_penalty=1.1, # Penalize repeated tokens
+ frequency_penalty=0.5, # Additional frequency penalty
+ presence_penalty=0.5, # Additional presence penalty
+)
+```
+
+
+
+
+
+```python
+params = SamplingParams(
+ presence_penalty=0.1, # Penalize token presence
+ frequency_penalty=0.1, # Penalize token frequency
+)
+```
+
+
+
+
+
+### పొడవు నియంత్రణ మరియు Stop Sequences
+
+జనరేట్ చేసే టెక్స్ట్ ఎంత పొడవు ఉండాలి, ఎప్పుడు generation ఆగాలి అనేదాన్ని కూడా నియంత్రించవచ్చు:
+
+
+
+
+
+```python
+client.generate(
+ "Generate a short paragraph",
+ max_new_tokens=100,
+ min_new_tokens=10,
+ stop_sequences=["\n\n", "###"],
+)
+```
+
+
+
+
+
+```python
+# Via OpenAI API
+response = client.completions.create(
+ model="smollm2-1.7b-instruct",
+ prompt="Generate a short paragraph",
+ max_tokens=100,
+ stop=["\n\n", "###"],
+)
+
+# Via direct library
+output = llm("Generate a short paragraph", max_tokens=100, stop=["\n\n", "###"])
+```
+
+
+
+
+
+```python
+params = SamplingParams(
+ max_tokens=100,
+ min_tokens=10,
+ stop=["###", "\n\n"],
+ ignore_eos=False,
+ skip_special_tokens=True,
+)
+```
+
+
+
+
+
+## మెమరీ నిర్వహణ
+
+సమర్థవంతమైన inference కోసం ఈ frameworks అన్నీ అభివృద్ధి చెందిన మెమరీ మేనేజ్మెంట్ విధానాలను ఉపయోగిస్తాయి.
+
+
+
+
+
+TGI, Flash Attention 2 మరియు continuous batching ను ఉపయోగిస్తుంది:
+
+```sh
+# Docker deployment with memory optimization
+docker run --gpus all -p 8080:80 \
+ --shm-size 1g \
+ ghcr.io/huggingface/text-generation-inference:latest \
+ --model-id HuggingFaceTB/SmolLM2-1.7B-Instruct \
+ --max-batch-total-tokens 8192 \
+ --max-input-length 4096
+```
+
+
+
+
+
+llama.cpp లో quantization మరియు optimized memory layout వాడుతుంది:
+
+```sh
+# Server with memory optimizations
+./server \
+ -m smollm2-1.7b-instruct.Q4_K_M.gguf \
+ --host 0.0.0.0 \
+ --port 8080 \
+ -c 2048 \ # Context size
+ --threads 4 \ # CPU threads
+ --n-gpu-layers 32 \ # Use more GPU layers for larger models
+ --mlock \ # Lock memory to prevent swapping
+ --cont-batching # Enable continuous batching
+```
+
+మీ GPU కి చాలా పెద్దగా ఉన్న మోడళ్ల కోసం CPU offloading ను ఉపయోగించవచ్చు:
+
+```sh
+./server \
+ -m smollm2-1.7b-instruct.Q4_K_M.gguf \
+ --n-gpu-layers 20 \ # Keep first 20 layers on GPU
+ --threads 8 # Use more CPU threads for CPU layers
+```
+
+
+
+
+
+vLLM, మెమరీని అత్యంత సమర్థవంతంగా నిర్వహించేందుకు PagedAttention ను ఉపయోగిస్తుంది:
+
+```python
+from vllm.engine.arg_utils import AsyncEngineArgs
+
+engine_args = AsyncEngineArgs(
+ model="HuggingFaceTB/SmolLM2-1.7B-Instruct",
+ gpu_memory_utilization=0.85,
+ max_num_batched_tokens=8192,
+ block_size=16,
+)
+
+llm = LLM(engine_args=engine_args)
+```
+
+
+
+
+
+## వనరులు (Resources)
+
+- [Text Generation Inference Documentation](https://huggingface.co/docs/text-generation-inference)
+- [TGI GitHub Repository](https://github.com/huggingface/text-generation-inference)
+- [vLLM Documentation](https://vllm.readthedocs.io/)
+- [vLLM GitHub Repository](https://github.com/vllm-project/vllm)
+- [PagedAttention Paper](https://arxiv.org/abs/2309.06180)
+- [llama.cpp GitHub Repository](https://github.com/ggerganov/llama.cpp)
+- [llama-cpp-python Repository](https://github.com/abetlen/llama-cpp-python)
diff --git a/chapters/te/chapter2/9.mdx b/chapters/te/chapter2/9.mdx
new file mode 100644
index 000000000..105832f12
--- /dev/null
+++ b/chapters/te/chapter2/9.mdx
@@ -0,0 +1,252 @@
+
+
+
+
+# అధ్యాయం ముగింపు క్విజ్[[end-of-chapter-quiz]]
+
+
+
+### 1. Language modeling పైప్లైన్లో స్టెప్స్ సరైన క్రమం ఏది?
+
+
+
+### 2. Base Transformer model output గా ఇచ్చే tensor కి ఎన్ని dimensions ఉంటాయి? అవి ఏవి?
+
+
+
+### 3. క్రిందివాటిలో subword tokenization కి ఉదాహరణలు ఏవి?
+
+
+
+### 4. Model head అంటే ఏమిటి?
+
+
+
+### 5. AutoModel అంటే ఏమిటి?
+
+AutoTrain product తో గలత చేయుతున్నారా?"
+ },
+ {
+ text: "ఇచ్చిన checkpoint ఆధారంగా సరైన architecture ని తిరిగి ఇవ్వగల object",
+ explain: "అచ్చం అదే:
+
+
+
+Flash Attention అనేది transformer models లోని attention mechanism ను ఆప్టిమైజ్ చేయడానికి ఉపయోగించే సాంకేతికత.
+మనం [అధ్యాయం 1.8](/course/chapter1/8) లో చర్చించినట్టుగా, attention కి quadratic complexity ఉండటం వలన, దీని computation మరియు memory వినియోగం ఎక్కువగా ఉంటుంది.
+
+Flash Attention యొక్క ప్రధాన ఆవిష్కరణ HBM (High Bandwidth Memory) మరియు SRAM cache మధ్య memory transfer ను తగ్గించడంలో ఉంది. సాధారణ attention లో ఈ transfers చాలా సార్లు జరుగుతూ bottleneck అవుతాయి.
+Flash Attention డేటాను ఒక్కసారి SRAM లోకి లోడ్ చేసి, calculations అంతా అక్కడే పూర్తి చేస్తుంది, దాంతో memory overhead చాలా తగ్గుతుంది.
+
+ఈ ప్రయోజనాలు training సమయంలో ఎక్కువగా కనిపించినా, inference సమయంలో కూడా VRAM వినియోగం తగ్గడం మరియు వేగం పెరగడం వంటి ప్రయోజనాలు అందిస్తుంది.
+
+
+
+**vLLM** పూర్తిగా వేరు విధానాన్ని అనుసరిస్తుంది — దీని ప్రత్యేకత *PagedAttention*.
+ఇది కంప్యూటర్ virtual memory లానే పనిచేస్తుంది: మోడల్ memory ను చిన్న చిన్న “pages” గా విభజిస్తుంది. దీని ద్వారా requests వేర్వేరు sizes అయినా memory ని వృథా చేయకుండా హ్యాండిల్ చేయవచ్చు.
+ఇది memory fragmentation ను తగ్గిస్తూ, KV cache ను సమర్థవంతంగా నిర్వహిస్తుంది, తద్వారా throughput భారీగా పెరుగుతుంది.
+
+
+
+PagedAttention, KV cache నిర్వహణలో ఉండే bottlenecks ను పరిష్కరించడానికి రూపొందించబడింది.
+LLM generation సమయంలో, ప్రతి token కి keys మరియు values (KV cache) నిల్వ చేయాలి. దీని memory చాలా పెద్దది అవుతుంది — ముఖ్యంగా long sequences లేదా concurrent requests వద్ద.
+
+vLLM యొక్క కీలక ఆవిష్కరణలు ఇవి:
+
+1. **Memory Paging** – KV cache ను పెద్ద continuous block లాగా కాకుండా చిన్న pages గా విభజించడం
+2. **Non-contiguous Storage** – GPU memory లో pages continuous గా ఉండాల్సిన అవసరం లేదు
+3. **Page Table** – ఏ pages ఏ sequence కు చెందినవి అనే సమాచారం నిర్వహించడం
+4. **Memory Sharing** – ఒక prompt కి సంబంధించిన KV cache pages ని అనేక sequences మధ్య share చేయడం
+
+ఈ పద్ధతి సంప్రదాయ inference పద్ధతుల కంటే *24x వరకు* ఎక్కువ throughput అందించగలదు.
+వివరంగా తెలుసుకోవాలంటే, [vLLM documentation](https://docs.vllm.ai/en/latest/design/kernel/paged_attention.html) చదవవచ్చు.
+
+
+
+**llama.cpp** అనేది అత్యంత ఆప్టిమైజ్ చేయబడిన C/C++ implementation. మొదట ఇది consumer hardware పై LLaMA మోడళ్లను రన్ చేయడానికి రూపొందించబడింది.
+ఇది CPU పై అత్యంత సమర్థవంతంగా పనిచేస్తుంది, అవసరమైతే GPU acceleration కూడా అందిస్తుంది.
+llama.cpp మోడల్ ను quantize చేసి చిన్న పరిమాణంలోకి మార్చుతుంది — అలా VRAM వినియోగం తగ్గి inference వేగం పెరుగుతుంది.
+
+
+
+Quantization అనేది మోడల్ weights ను FP32/FP16 నుండి తక్కువ precision (INT8, 4-bit మొదలైనవి) కు మార్చే ప్రక్రియ.
+ఇది memory వినియోగాన్ని గణనీయంగా తగ్గించి inference వేగాన్ని పెంచుతుంది., accuracy లో తక్కువ నష్టం మాత్రమే ఉంటుంది.
+
+llama.cpp లోని ముఖ్యమైన quantization ప్రయోజనాలు:
+
+1. **అనేక precision స్థాయిలు** – INT8, 4-bit, 3-bit, 2-bit వరకు
+2. **GGML/GGUF ఫార్మాట్లు** – quantized inference కోసం ఆప్టిమైజ్ చేసిన టెన్సర్ ఫార్మాట్లు
+3. **Mixed precision** – మోడల్లో వేర్వేరు భాగాలకు వేర్వేరు quantization స్థాయిలు
+4. **CPU optimizations** – AVX2, AVX-512, NEON వంటి CPU నిర్మాణాల (architectures) కోసం ఆప్టిమైజ్ చేసిన kernels
+
+ఈ విధానం, తక్కువ memory ఉన్న consumer devices పై కూడా పెద్ద మోడళ్లను రన్ చేయడానికి మార్గాన్ని అందిస్తుంది.
+
+
+
+### Deployment మరియు Integration
+
+ఇప్పుడు frameworks deployment మరియు integration పరంగా ఎలా భిన్నంగా ఉన్నాయో చూద్దాం.
+
+**TGI** enterprise-స్థాయి deployment లో అత్యుత్తమం.
+ఇది production కి అవసరమైన వాటిని built-in గా అందిస్తుంది — Kubernetes support, monitoring (Prometheus/Grafana), autoscaling, content filtering, rate limiting, security features మొదలైనవి.
+అంతేకాకుండా enterprise-grade logging కూడా కలిగి ఉంది.
+
+**vLLM** flexible మరియు developer-friendly గా రూపొందించబడింది.
+ఇది Python ఆధారంగా పనిచేస్తుంది మరియు మీ existing applications లో OpenAI API స్థానంలో సులభంగా plug చేయవచ్చు.
+Clusters నిర్వహణ కోసం Ray తో బాగా పని చేస్తుంది.
+
+**llama.cpp** సాదాసీదా, తేలికైన server implementation కలిగి ఉంది.
+Python frameworks ను install చేయడం కష్టమైన పరిసరాల్లో కూడా deployment సులభం.
+ఇది OpenAI-compatible API కూడా అందిస్తుంది, కానీ resource వినియోగం చాలా తక్కువ.
+
+## ప్రారంభించడం
+
+ఇప్పుడు ఈ frameworks ను ఎలా ఉపయోగించాలో — సంస్థాపన (installation) నుండి deployment వరకూ — చూద్దాం.
+
+### సంస్థాపన మరియు ప్రాథమిక సెటప్
+
+
+
+
+
+TGI ను Hugging Face ecosystem తో బాగా integrate చేశారు, మరియు సంస్థాపన చాలా సులభం.
+
+మొదట, Docker తో TGI server ను ప్రారంభించండి:
+
+```sh
+docker run --gpus all \
+ --shm-size 1g \
+ -p 8080:80 \
+ -v ~/.cache/huggingface:/data \
+ ghcr.io/huggingface/text-generation-inference:latest \
+ --model-id HuggingFaceTB/SmolLM2-360M-Instruct
+```
+
+తరువాత Hugging Face InferenceClient తో ఇంటరాక్ట్ అవండి:
+
+```python
+from huggingface_hub import InferenceClient
+
+# Initialize client pointing to TGI endpoint
+client = InferenceClient(
+ model="http://localhost:8080", # URL to the TGI server
+)
+
+# Text generation
+response = client.text_generation(
+ "Tell me a story",
+ max_new_tokens=100,
+ temperature=0.7,
+ top_p=0.95,
+ details=True,
+ stop_sequences=[],
+)
+print(response.generated_text)
+
+# For chat format
+response = client.chat_completion(
+ messages=[
+ {"role": "system", "content": "You are a helpful assistant."},
+ {"role": "user", "content": "Tell me a story"},
+ ],
+ max_tokens=100,
+ temperature=0.7,
+ top_p=0.95,
+)
+print(response.choices[0].message.content)
+```
+
+లేదా OpenAI client ఉపయోగించవచ్చు:
+
+```python
+from openai import OpenAI
+
+# Initialize client pointing to TGI endpoint
+client = OpenAI(
+ base_url="http://localhost:8080/v1", # Make sure to include /v1
+ api_key="not-needed", # TGI doesn't require an API key by default
+)
+
+# Chat completion
+response = client.chat.completions.create(
+ model="HuggingFaceTB/SmolLM2-360M-Instruct",
+ messages=[
+ {"role": "system", "content": "You are a helpful assistant."},
+ {"role": "user", "content": "Tell me a story"},
+ ],
+ max_tokens=100,
+ temperature=0.7,
+ top_p=0.95,
+)
+print(response.choices[0].message.content)
+```
+
+
+
+
+
+llama.cpp సంస్థాపన చాలా తేలికగా ఉంటుంది; CPU మరియు GPU inference రెండింటిని సపోర్ట్ చేస్తుంది.
+
+మొదట, llama.cpp ని build చేయండి:
+
+```sh
+# Clone the repository
+git clone https://github.com/ggerganov/llama.cpp
+cd llama.cpp
+
+# Build the project
+make
+
+# Download the SmolLM2-1.7B-Instruct-GGUF model
+curl -L -O https://huggingface.co/HuggingFaceTB/SmolLM2-1.7B-Instruct-GGUF/resolve/main/smollm2-1.7b-instruct.Q4_K_M.gguf
+```
+
+OpenAI-compatible server ను ప్రారంభించండి:
+
+```sh
+# Start the server
+./server \
+ -m smollm2-1.7b-instruct.Q4_K_M.gguf \
+ --host 0.0.0.0 \
+ --port 8080 \
+ -c 4096 \
+ --n-gpu-layers 0 # Set to a higher number to use GPU
+```
+
+InferenceClient తో interact చేయండి:
+
+```python
+from huggingface_hub import InferenceClient
+
+# Initialize client pointing to llama.cpp server
+client = InferenceClient(
+ model="http://localhost:8080/v1", # URL to the llama.cpp server
+ token="sk-no-key-required", # llama.cpp server requires this placeholder
+)
+
+# Text generation
+response = client.text_generation(
+ "Tell me a story",
+ max_new_tokens=100,
+ temperature=0.7,
+ top_p=0.95,
+ details=True,
+)
+print(response.generated_text)
+
+# For chat format
+response = client.chat_completion(
+ messages=[
+ {"role": "system", "content": "You are a helpful assistant."},
+ {"role": "user", "content": "Tell me a story"},
+ ],
+ max_tokens=100,
+ temperature=0.7,
+ top_p=0.95,
+)
+print(response.choices[0].message.content)
+```
+
+లేదా OpenAI client ఉపయోగించండి:
+
+```python
+from openai import OpenAI
+
+# Initialize client pointing to llama.cpp server
+client = OpenAI(
+ base_url="http://localhost:8080/v1",
+ api_key="sk-no-key-required", # llama.cpp server requires this placeholder
+)
+
+# Chat completion
+response = client.chat.completions.create(
+ model="smollm2-1.7b-instruct", # Model identifier can be anything as server only loads one model
+ messages=[
+ {"role": "system", "content": "You are a helpful assistant."},
+ {"role": "user", "content": "Tell me a story"},
+ ],
+ max_tokens=100,
+ temperature=0.7,
+ top_p=0.95,
+)
+print(response.choices[0].message.content)
+```
+
+
+
+
+
+vLLM సంస్థాపన కూడా అత్యంత సులభం. ఇది OpenAI-compatible API మరియు native Python interface రెండింటినీ అందిస్తుంది.
+
+మొదట, vLLM server ను ప్రారంభించండి:
+
+```sh
+python -m vllm.entrypoints.openai.api_server \
+ --model HuggingFaceTB/SmolLM2-360M-Instruct \
+ --host 0.0.0.0 \
+ --port 8000
+```
+
+InferenceClient తో ఉపయోగించండి:
+
+```python
+from huggingface_hub import InferenceClient
+
+# Initialize client pointing to vLLM endpoint
+client = InferenceClient(
+ model="http://localhost:8000/v1", # URL to the vLLM server
+)
+
+# Text generation
+response = client.text_generation(
+ "Tell me a story",
+ max_new_tokens=100,
+ temperature=0.7,
+ top_p=0.95,
+ details=True,
+)
+print(response.generated_text)
+
+# For chat format
+response = client.chat_completion(
+ messages=[
+ {"role": "system", "content": "You are a helpful assistant."},
+ {"role": "user", "content": "Tell me a story"},
+ ],
+ max_tokens=100,
+ temperature=0.7,
+ top_p=0.95,
+)
+print(response.choices[0].message.content)
+```
+
+లేదా OpenAI client:
+
+```python
+from openai import OpenAI
+
+# Initialize client pointing to vLLM endpoint
+client = OpenAI(
+ base_url="http://localhost:8000/v1",
+ api_key="not-needed", # vLLM doesn't require an API key by default
+)
+
+# Chat completion
+response = client.chat.completions.create(
+ model="HuggingFaceTB/SmolLM2-360M-Instruct",
+ messages=[
+ {"role": "system", "content": "You are a helpful assistant."},
+ {"role": "user", "content": "Tell me a story"},
+ ],
+ max_tokens=100,
+ temperature=0.7,
+ top_p=0.95,
+)
+print(response.choices[0].message.content)
+```
+
+
+
+
+
+### ప్రాథమిక టెక్స్ట్ జనరేషన్
+
+ఇప్పుడు frameworks లో text generation ఎలా చేయాలో చూద్దాం.
+
+
+
+
+
+మొదట, అభివృద్ధి చెందిన parameters తో TGI deploy చేయండి:
+
+```sh
+docker run --gpus all \
+ --shm-size 1g \
+ -p 8080:80 \
+ -v ~/.cache/huggingface:/data \
+ ghcr.io/huggingface/text-generation-inference:latest \
+ --model-id HuggingFaceTB/SmolLM2-360M-Instruct \
+ --max-total-tokens 4096 \
+ --max-input-length 3072 \
+ --max-batch-total-tokens 8192 \
+ --waiting-served-ratio 1.2
+```
+
+InferenceClient తో generation చేయండి:
+
+```python
+from huggingface_hub import InferenceClient
+
+client = InferenceClient(model="http://localhost:8080")
+
+# Advanced parameters example
+response = client.chat_completion(
+ messages=[
+ {"role": "system", "content": "You are a creative storyteller."},
+ {"role": "user", "content": "Write a creative story"},
+ ],
+ temperature=0.8,
+ max_tokens=200,
+ top_p=0.95,
+)
+print(response.choices[0].message.content)
+
+# Raw text generation
+response = client.text_generation(
+ "Write a creative story about space exploration",
+ max_new_tokens=200,
+ temperature=0.8,
+ top_p=0.95,
+ repetition_penalty=1.1,
+ do_sample=True,
+ details=True,
+)
+print(response.generated_text)
+```
+
+లేదా OpenAI client:
+```python
+from openai import OpenAI
+
+client = OpenAI(base_url="http://localhost:8080/v1", api_key="not-needed")
+
+# Advanced parameters example
+response = client.chat.completions.create(
+ model="HuggingFaceTB/SmolLM2-360M-Instruct",
+ messages=[
+ {"role": "system", "content": "You are a creative storyteller."},
+ {"role": "user", "content": "Write a creative story"},
+ ],
+ temperature=0.8, # Higher for more creativity
+)
+print(response.choices[0].message.content)
+```
+
+
+
+
+
+llama.cpp లో server launch సమయంలో advanced parameters సెట్ చేయవచ్చు:
+
+```sh
+./server \
+ -m smollm2-1.7b-instruct.Q4_K_M.gguf \
+ --host 0.0.0.0 \
+ --port 8080 \
+ -c 4096 \ # Context size
+ --threads 8 \ # CPU threads to use
+ --batch-size 512 \ # Batch size for prompt evaluation
+ --n-gpu-layers 0 # GPU layers (0 = CPU only)
+```
+
+InferenceClient తో ఉపయోగించండి:
+
+```python
+from huggingface_hub import InferenceClient
+
+client = InferenceClient(model="http://localhost:8080/v1", token="sk-no-key-required")
+
+# Advanced parameters example
+response = client.chat_completion(
+ messages=[
+ {"role": "system", "content": "You are a creative storyteller."},
+ {"role": "user", "content": "Write a creative story"},
+ ],
+ temperature=0.8,
+ max_tokens=200,
+ top_p=0.95,
+)
+print(response.choices[0].message.content)
+
+# For direct text generation
+response = client.text_generation(
+ "Write a creative story about space exploration",
+ max_new_tokens=200,
+ temperature=0.8,
+ top_p=0.95,
+ repetition_penalty=1.1,
+ details=True,
+)
+print(response.generated_text)
+```
+
+లేదా నమూనా పారామితులపై నియంత్రణతో జనరేషన్ కోసం OpenAI క్లయింట్ని ఉపయోగించండి:
+
+```python
+from openai import OpenAI
+
+client = OpenAI(base_url="http://localhost:8080/v1", api_key="sk-no-key-required")
+
+# Advanced parameters example
+response = client.chat.completions.create(
+ model="smollm2-1.7b-instruct",
+ messages=[
+ {"role": "system", "content": "You are a creative storyteller."},
+ {"role": "user", "content": "Write a creative story"},
+ ],
+ temperature=0.8, # Higher for more creativity
+ top_p=0.95, # Nucleus sampling probability
+ frequency_penalty=0.5, # Reduce repetition of frequent tokens
+ presence_penalty=0.5, # Reduce repetition by penalizing tokens already present
+ max_tokens=200, # Maximum generation length
+)
+print(response.choices[0].message.content)
+```
+
+అదనంగా, llama.cpp native library తో మరింత నియంత్రణ పొందవచ్చు:
+
+```python
+# Using llama-cpp-python package for direct model access
+from llama_cpp import Llama
+
+# Load the model
+llm = Llama(
+ model_path="smollm2-1.7b-instruct.Q4_K_M.gguf",
+ n_ctx=4096, # Context window size
+ n_threads=8, # CPU threads
+ n_gpu_layers=0, # GPU layers (0 = CPU only)
+)
+
+# Format prompt according to the model's expected format
+prompt = """<|im_start|>system
+You are a creative storyteller.
+<|im_end|>
+<|im_start|>user
+Write a creative story
+<|im_end|>
+<|im_start|>assistant
+"""
+
+# Generate response with precise parameter control
+output = llm(
+ prompt,
+ max_tokens=200,
+ temperature=0.8,
+ top_p=0.95,
+ frequency_penalty=0.5,
+ presence_penalty=0.5,
+ stop=["<|im_end|>"],
+)
+
+print(output["choices"][0]["text"])
+```
+
+
+
+
+
+vLLM తో అధునాతన ఉపయోగం కోసం, మీరు InferenceClient ని ఉపయోగించవచ్చు:
+
+```python
+from huggingface_hub import InferenceClient
+
+client = InferenceClient(model="http://localhost:8000/v1")
+
+# Advanced parameters example
+response = client.chat_completion(
+ messages=[
+ {"role": "system", "content": "You are a creative storyteller."},
+ {"role": "user", "content": "Write a creative story"},
+ ],
+ temperature=0.8,
+ max_tokens=200,
+ top_p=0.95,
+)
+print(response.choices[0].message.content)
+
+# For direct text generation
+response = client.text_generation(
+ "Write a creative story about space exploration",
+ max_new_tokens=200,
+ temperature=0.8,
+ top_p=0.95,
+ details=True,
+)
+print(response.generated_text)
+```
+
+మీరు OpenAI client కూడా ఉపయోగించవచ్చు:
+
+```python
+from openai import OpenAI
+
+client = OpenAI(base_url="http://localhost:8000/v1", api_key="not-needed")
+
+# Advanced parameters example
+response = client.chat.completions.create(
+ model="HuggingFaceTB/SmolLM2-360M-Instruct",
+ messages=[
+ {"role": "system", "content": "You are a creative storyteller."},
+ {"role": "user", "content": "Write a creative story"},
+ ],
+ temperature=0.8,
+ top_p=0.95,
+ max_tokens=200,
+)
+print(response.choices[0].message.content)
+```
+
+vLLM లో స్థానిక పైథాన్ interface కూడా ఉంది:
+
+```python
+from vllm import LLM, SamplingParams
+
+# Initialize the model with advanced parameters
+llm = LLM(
+ model="HuggingFaceTB/SmolLM2-360M-Instruct",
+ gpu_memory_utilization=0.85,
+ max_num_batched_tokens=8192,
+ max_num_seqs=256,
+ block_size=16,
+)
+
+# Configure sampling parameters
+sampling_params = SamplingParams(
+ temperature=0.8, # Higher for more creativity
+ top_p=0.95, # Consider top 95% probability mass
+ max_tokens=100, # Maximum length
+ presence_penalty=1.1, # Reduce repetition
+ frequency_penalty=1.1, # Reduce repetition
+ stop=["\n\n", "###"], # Stop sequences
+)
+
+# Generate text
+prompt = "Write a creative story"
+outputs = llm.generate(prompt, sampling_params)
+print(outputs[0].outputs[0].text)
+
+# For chat-style interactions
+chat_prompt = [
+ {"role": "system", "content": "You are a creative storyteller."},
+ {"role": "user", "content": "Write a creative story"},
+]
+formatted_prompt = llm.get_chat_template()(chat_prompt) # Uses model's chat template
+outputs = llm.generate(formatted_prompt, sampling_params)
+print(outputs[0].outputs[0].text)
+```
+
+
+
+
+
+## అధునాతన జనరేషన్ నియంత్రణ
+
+### Token ఎంపిక మరియు Sampling
+
+టెక్స్ట్ను జనరేట్ చేసే ప్రక్రియలో, ప్రతి దశలో వచ్చే తదుపరి token ను ఎంపిక చేయాలి. ఈ ఎంపికను పలు నియంత్రణ పరామితుల ద్వారా ప్రభావితం చేయవచ్చు:
+
+1. **Raw Logits**: ప్రతి token కోసం మోడల్ ఇచ్చే ప్రారంభ probability విలువలు
+2. **Temperature**: యాదృచ్ఛికతను నియంత్రిస్తుంది (విలువ ఎక్కువైతే output మరింత creative గా ఉంటుంది)
+3. **Top-p (Nucleus) Sampling**: మొత్తం probability లో X% వచ్చే వరకు ఉన్న అత్యుత్తమ tokens ను మాత్రమే పరిగణలోకి తీసుకోవడం
+4. **Top-k Filtering**: అత్యంత సాధ్యమైన k tokens కు selection ను పరిమితం చేయడం
+
+ఈ పరామితులను ఎలా సెట్ చేయాలో ఇక్కడ చూపుతున్నాం:
+
+
+
+
+
+```python
+client.generate(
+ "Write a creative story",
+ temperature=0.8, # Higher for more creativity
+ top_p=0.95, # Consider top 95% probability mass
+ top_k=50, # Consider top 50 tokens
+ max_new_tokens=100, # Maximum length
+ repetition_penalty=1.1, # Reduce repetition
+)
+```
+
+
+
+
+
+```python
+# Via OpenAI API compatibility
+response = client.completions.create(
+ model="smollm2-1.7b-instruct", # Model name (can be any string for llama.cpp server)
+ prompt="Write a creative story",
+ temperature=0.8, # Higher for more creativity
+ top_p=0.95, # Consider top 95% probability mass
+ frequency_penalty=1.1, # Reduce repetition
+ presence_penalty=0.1, # Reduce repetition
+ max_tokens=100, # Maximum length
+)
+
+# Via llama-cpp-python direct access
+output = llm(
+ "Write a creative story",
+ temperature=0.8,
+ top_p=0.95,
+ top_k=50,
+ max_tokens=100,
+ repeat_penalty=1.1,
+)
+```
+
+
+
+
+
+```python
+params = SamplingParams(
+ temperature=0.8, # Higher for more creativity
+ top_p=0.95, # Consider top 95% probability mass
+ top_k=50, # Consider top 50 tokens
+ max_tokens=100, # Maximum length
+ presence_penalty=0.1, # Reduce repetition
+)
+llm.generate("Write a creative story", sampling_params=params)
+```
+
+
+
+
+
+### పునరావృతం నివారణ (Controlling Repetition)
+
+పునరావృతమైన లేదా ఒకే విధమైన టెక్స్ట్ను మోడల్ నిరంతరం ఉత్పత్తి చేయకుండా నిలువరించడానికి frameworks నియంత్రణ పద్ధతులు అందిస్తాయి:
+
+
+
+
+
+```python
+client.generate(
+ "Write a varied text",
+ repetition_penalty=1.1, # Penalize repeated tokens
+ no_repeat_ngram_size=3, # Prevent 3-gram repetition
+)
+```
+
+
+
+
+
+```python
+# Via OpenAI API
+response = client.completions.create(
+ model="smollm2-1.7b-instruct",
+ prompt="Write a varied text",
+ frequency_penalty=1.1, # Penalize frequent tokens
+ presence_penalty=0.8, # Penalize tokens already present
+)
+
+# Via direct library
+output = llm(
+ "Write a varied text",
+ repeat_penalty=1.1, # Penalize repeated tokens
+ frequency_penalty=0.5, # Additional frequency penalty
+ presence_penalty=0.5, # Additional presence penalty
+)
+```
+
+
+
+
+
+```python
+params = SamplingParams(
+ presence_penalty=0.1, # Penalize token presence
+ frequency_penalty=0.1, # Penalize token frequency
+)
+```
+
+
+
+
+
+### పొడవు నియంత్రణ మరియు Stop Sequences
+
+జనరేట్ చేసే టెక్స్ట్ ఎంత పొడవు ఉండాలి, ఎప్పుడు generation ఆగాలి అనేదాన్ని కూడా నియంత్రించవచ్చు:
+
+
+
+
+
+```python
+client.generate(
+ "Generate a short paragraph",
+ max_new_tokens=100,
+ min_new_tokens=10,
+ stop_sequences=["\n\n", "###"],
+)
+```
+
+
+
+
+
+```python
+# Via OpenAI API
+response = client.completions.create(
+ model="smollm2-1.7b-instruct",
+ prompt="Generate a short paragraph",
+ max_tokens=100,
+ stop=["\n\n", "###"],
+)
+
+# Via direct library
+output = llm("Generate a short paragraph", max_tokens=100, stop=["\n\n", "###"])
+```
+
+
+
+
+
+```python
+params = SamplingParams(
+ max_tokens=100,
+ min_tokens=10,
+ stop=["###", "\n\n"],
+ ignore_eos=False,
+ skip_special_tokens=True,
+)
+```
+
+
+
+
+
+## మెమరీ నిర్వహణ
+
+సమర్థవంతమైన inference కోసం ఈ frameworks అన్నీ అభివృద్ధి చెందిన మెమరీ మేనేజ్మెంట్ విధానాలను ఉపయోగిస్తాయి.
+
+
+
+
+
+TGI, Flash Attention 2 మరియు continuous batching ను ఉపయోగిస్తుంది:
+
+```sh
+# Docker deployment with memory optimization
+docker run --gpus all -p 8080:80 \
+ --shm-size 1g \
+ ghcr.io/huggingface/text-generation-inference:latest \
+ --model-id HuggingFaceTB/SmolLM2-1.7B-Instruct \
+ --max-batch-total-tokens 8192 \
+ --max-input-length 4096
+```
+
+
+
+
+
+llama.cpp లో quantization మరియు optimized memory layout వాడుతుంది:
+
+```sh
+# Server with memory optimizations
+./server \
+ -m smollm2-1.7b-instruct.Q4_K_M.gguf \
+ --host 0.0.0.0 \
+ --port 8080 \
+ -c 2048 \ # Context size
+ --threads 4 \ # CPU threads
+ --n-gpu-layers 32 \ # Use more GPU layers for larger models
+ --mlock \ # Lock memory to prevent swapping
+ --cont-batching # Enable continuous batching
+```
+
+మీ GPU కి చాలా పెద్దగా ఉన్న మోడళ్ల కోసం CPU offloading ను ఉపయోగించవచ్చు:
+
+```sh
+./server \
+ -m smollm2-1.7b-instruct.Q4_K_M.gguf \
+ --n-gpu-layers 20 \ # Keep first 20 layers on GPU
+ --threads 8 # Use more CPU threads for CPU layers
+```
+
+
+
+
+
+vLLM, మెమరీని అత్యంత సమర్థవంతంగా నిర్వహించేందుకు PagedAttention ను ఉపయోగిస్తుంది:
+
+```python
+from vllm.engine.arg_utils import AsyncEngineArgs
+
+engine_args = AsyncEngineArgs(
+ model="HuggingFaceTB/SmolLM2-1.7B-Instruct",
+ gpu_memory_utilization=0.85,
+ max_num_batched_tokens=8192,
+ block_size=16,
+)
+
+llm = LLM(engine_args=engine_args)
+```
+
+
+
+
+
+## వనరులు (Resources)
+
+- [Text Generation Inference Documentation](https://huggingface.co/docs/text-generation-inference)
+- [TGI GitHub Repository](https://github.com/huggingface/text-generation-inference)
+- [vLLM Documentation](https://vllm.readthedocs.io/)
+- [vLLM GitHub Repository](https://github.com/vllm-project/vllm)
+- [PagedAttention Paper](https://arxiv.org/abs/2309.06180)
+- [llama.cpp GitHub Repository](https://github.com/ggerganov/llama.cpp)
+- [llama-cpp-python Repository](https://github.com/abetlen/llama-cpp-python)
diff --git a/chapters/te/chapter2/9.mdx b/chapters/te/chapter2/9.mdx
new file mode 100644
index 000000000..105832f12
--- /dev/null
+++ b/chapters/te/chapter2/9.mdx
@@ -0,0 +1,252 @@
+
+
+
+
+# అధ్యాయం ముగింపు క్విజ్[[end-of-chapter-quiz]]
+
+
+
+### 1. Language modeling పైప్లైన్లో స్టెప్స్ సరైన క్రమం ఏది?
+
+
+
+### 2. Base Transformer model output గా ఇచ్చే tensor కి ఎన్ని dimensions ఉంటాయి? అవి ఏవి?
+
+
+
+### 3. క్రిందివాటిలో subword tokenization కి ఉదాహరణలు ఏవి?
+
+
+
+### 4. Model head అంటే ఏమిటి?
+
+
+
+### 5. AutoModel అంటే ఏమిటి?
+
+AutoTrain product తో గలత చేయుతున్నారా?"
+ },
+ {
+ text: "ఇచ్చిన checkpoint ఆధారంగా సరైన architecture ని తిరిగి ఇవ్వగల object",
+ explain: "అచ్చం అదే: AutoModel కి ఏ checkpoint నుండి initialize కావాలో తెలిస్తే, అది సరైన architecture ని ఎంచుకుని load చేస్తుంది.",
+ correct: true
+ },
+ {
+ text: "Inputs ఏ language లో ఉన్నాయో ఆటోమేటిక్గా గుర్తించి, దానికి సరిపోయే weights ని load చేసుకునే model",
+ explain: "కొన్ని checkpoints మరియు models ఒకటి కంటే ఎక్కువ languages ను హ్యాండిల్ చేయగలుగుతాయి; కానీ language ఆధారంగా checkpoint ని ఆటోమేటిక్గా ఎంచుకునే built-in tools లేవు. మీ task కి సరైన checkpoint కోసం Model Hub కి వెళ్లాలి!"
+ }
+ ]}
+/>
+
+### 6. వేర్వేరు పొడవుల sequences ని ఒకే batch లో కలిపేటప్పుడు, ఎలాంటి techniques గురించి తెలుసుకుని ఉండాలి?
+
+
+
+### 7. Sequence classification model ఇచ్చే logits మీద SoftMax function వాడటంలో అసలు ప్రయోజనం ఏమిటి?
+
+
+
+### 8. Tokenizer API లో ప్రధానంగా ఉపయోగించే method ఏది?
+
+encode, ఎందుకంటే అది text ను IDs గా మరియు IDs ను predictions గా మార్చగలదు",
+ explain: "తప్పు! encode method tokenizers మీద ఉంది, కానీ models మీద లేదు."
+ },
+ {
+ text: "Tokenizer object ని నేరుగా కాల్ చేయడం.",
+ explain: "ఖచ్చితంగా! Tokenizer లోని call method చాల పవర్ఫుల్—it చాలా పనులు హ్యాండిల్ చేయగలదు. Model నుండి predictions తీసుకోడానికి కూడా ఇదే method వాడతాం.",
+ correct: true
+ },
+ {
+ text: "pad",
+ explain: "తప్పు! Padding చాలా ఉపయోగకరమైనది, కానీ tokenizer API లో ఇది ఒక భాగం మాత్రమే."
+ },
+ {
+ text: "tokenize",
+ explain: "tokenize method బాగా ఉపయోగపడుతుంది, కానీ tokenizer API లో core method కాదు."
+ }
+ ]}
+/>
+
+### 9. ఈ code sample లో result variable లో ఏముంది?
+
+```py
+from transformers import AutoTokenizer
+
+tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
+result = tokenizer.tokenize("Hello!")
+```
+
+call లేదా convert_tokens_to_ids methods వాడాలి!"
+ },
+ {
+ text: "అన్ని tokens ని కలిపిన ఒకే string",
+ explain: "అలా చేయడం suboptimal; అసలు లక్ష్యం string ని అనేక tokens గా విడదీయడమే."
+ }
+ ]}
+/>
+
+### 10. ఈ code లో ఏదైనా తప్పు ఉందా?
+
+```py
+from transformers import AutoTokenizer, AutoModel
+
+tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
+model = AutoModel.from_pretrained("gpt2")
+
+encoded = tokenizer("Hey!", return_tensors="pt")
+result = model(**encoded)
+```
+
+