Prediction of student behavior has been a prominent area of research in learning analytics and a major concern for higher education institutions and ed tech companies alike. It is the bedrock of methodology within the world of cognitive tutors and these methods have been exported to other areas within the education technology landscape. The ability to predict what a student is likely to do in the future so that interventions can be tailored to them has seen major growth and investment, though implementation is non-trivial and expensive. Although some institutions, such as Purdue University, have seen success we are yet to see widespread adoption of these approaches as they tend to be highly institution specific and require very concrete outcomes to be useful.
I have built three prediction models within the classification tree type, in order to predict if students enrolled into particular courses in the semester complete the course or not. This enables us to understand how better to allocate valuable resources while allowing students to have the freedom to choose and sample courses.
The data used in this project comes from a university's registrar and is first run through a scatterplot matrix in order to do an initial visualization of the available information.
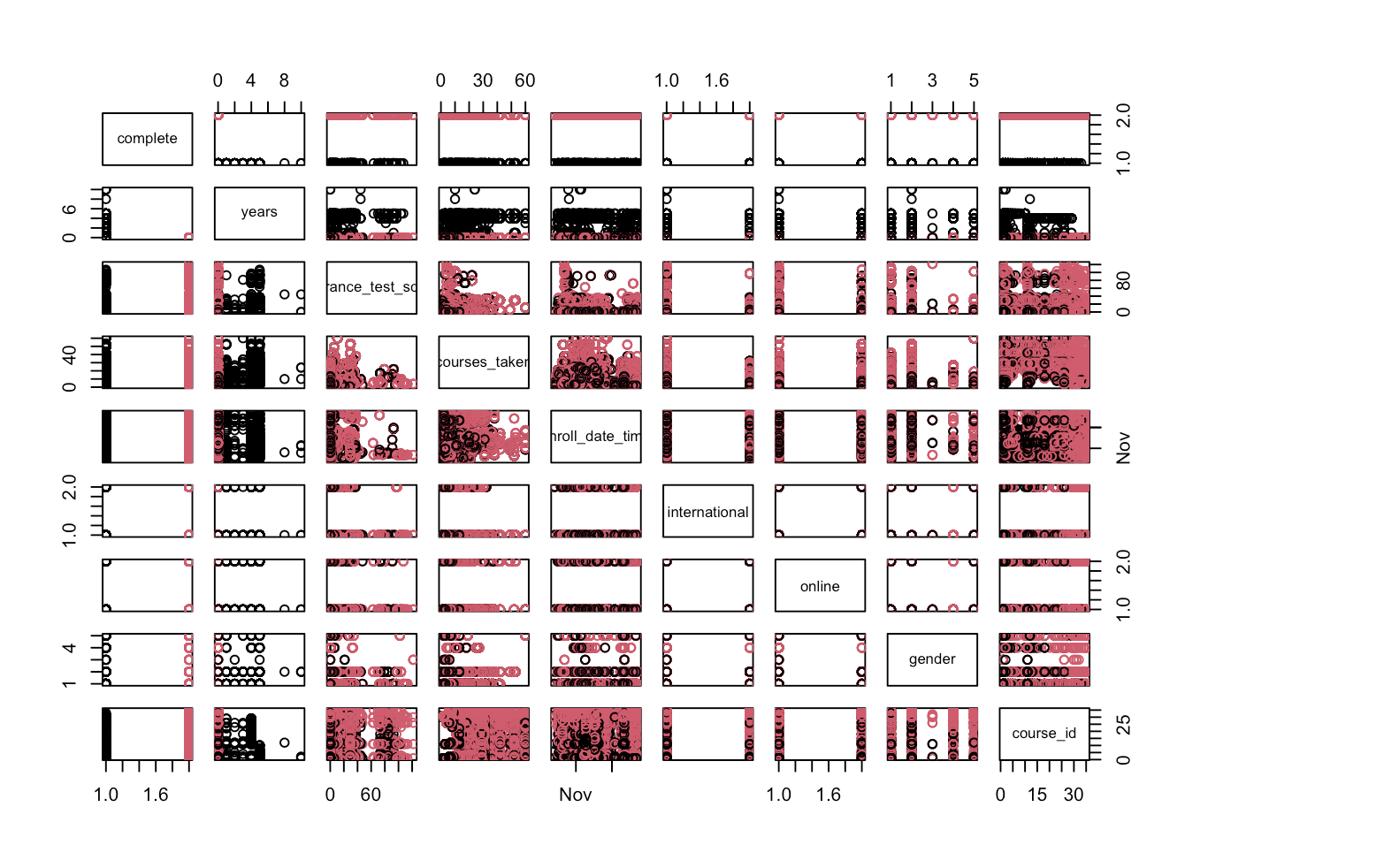
We notice that for the categorical variables, we are unable to gather meaningful visualization with a scatterplot, hence we use a jitter. Note that complete, our desired variable of interest which denotes if a student completes a course or not, is a categorical variable.
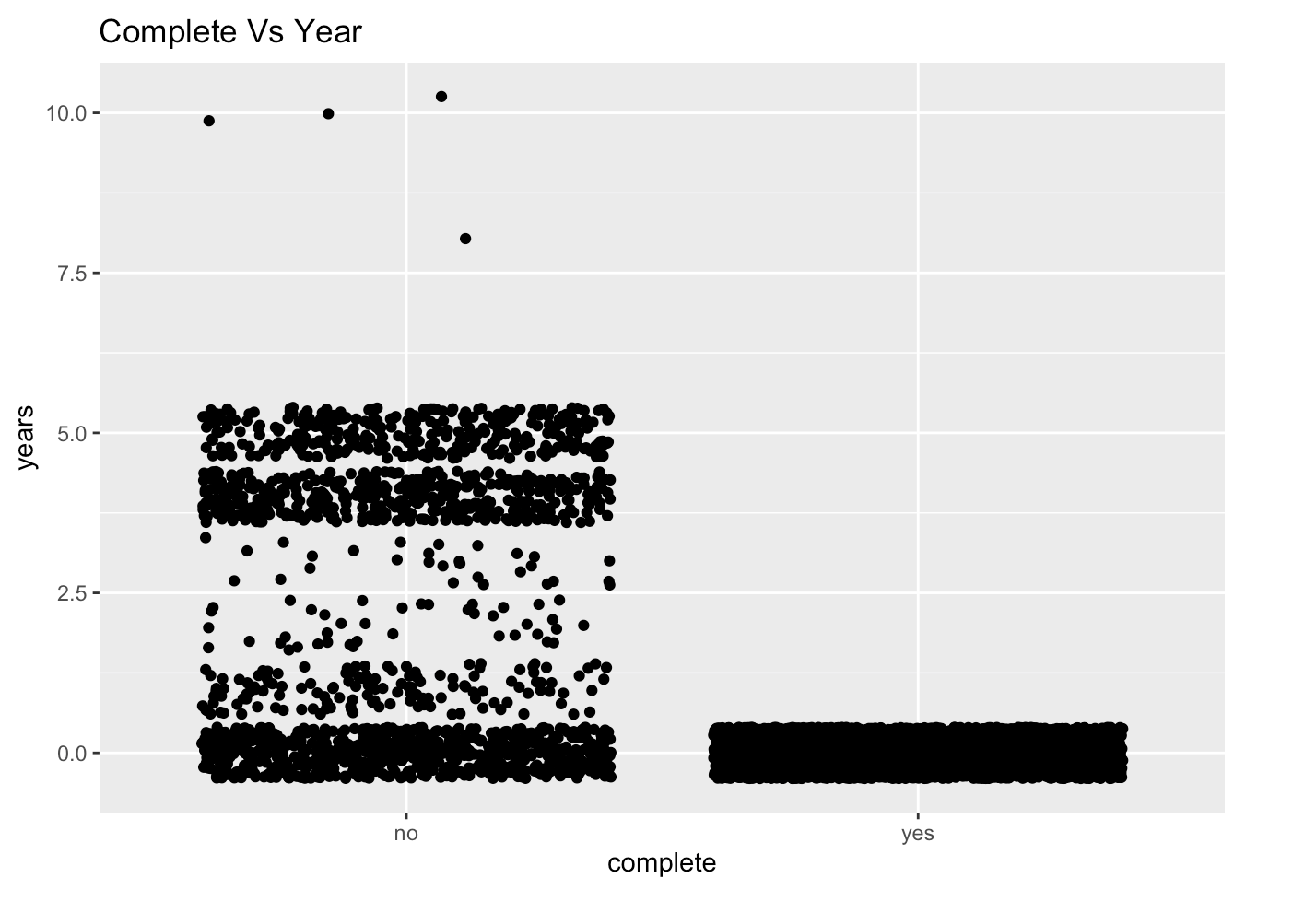
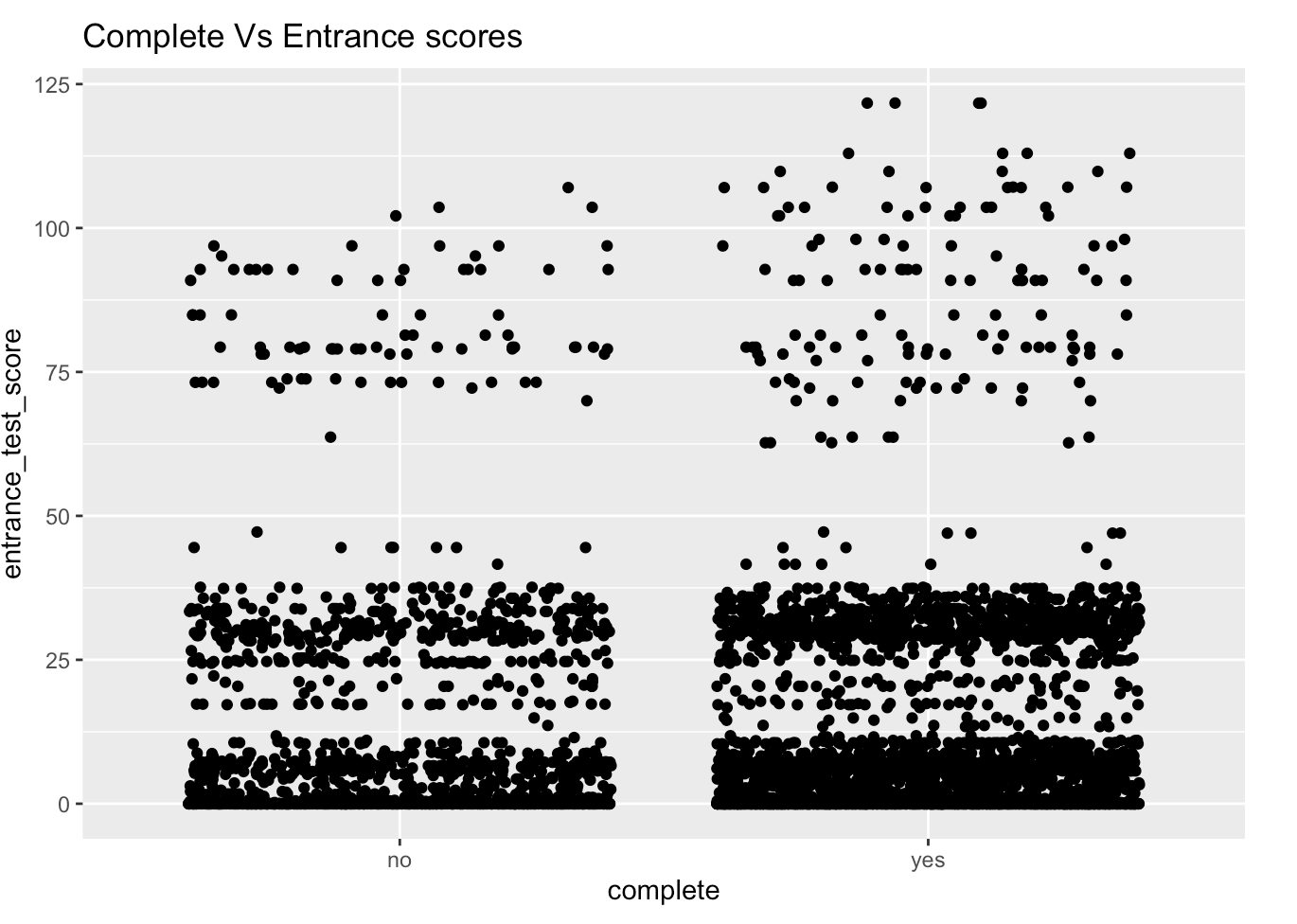
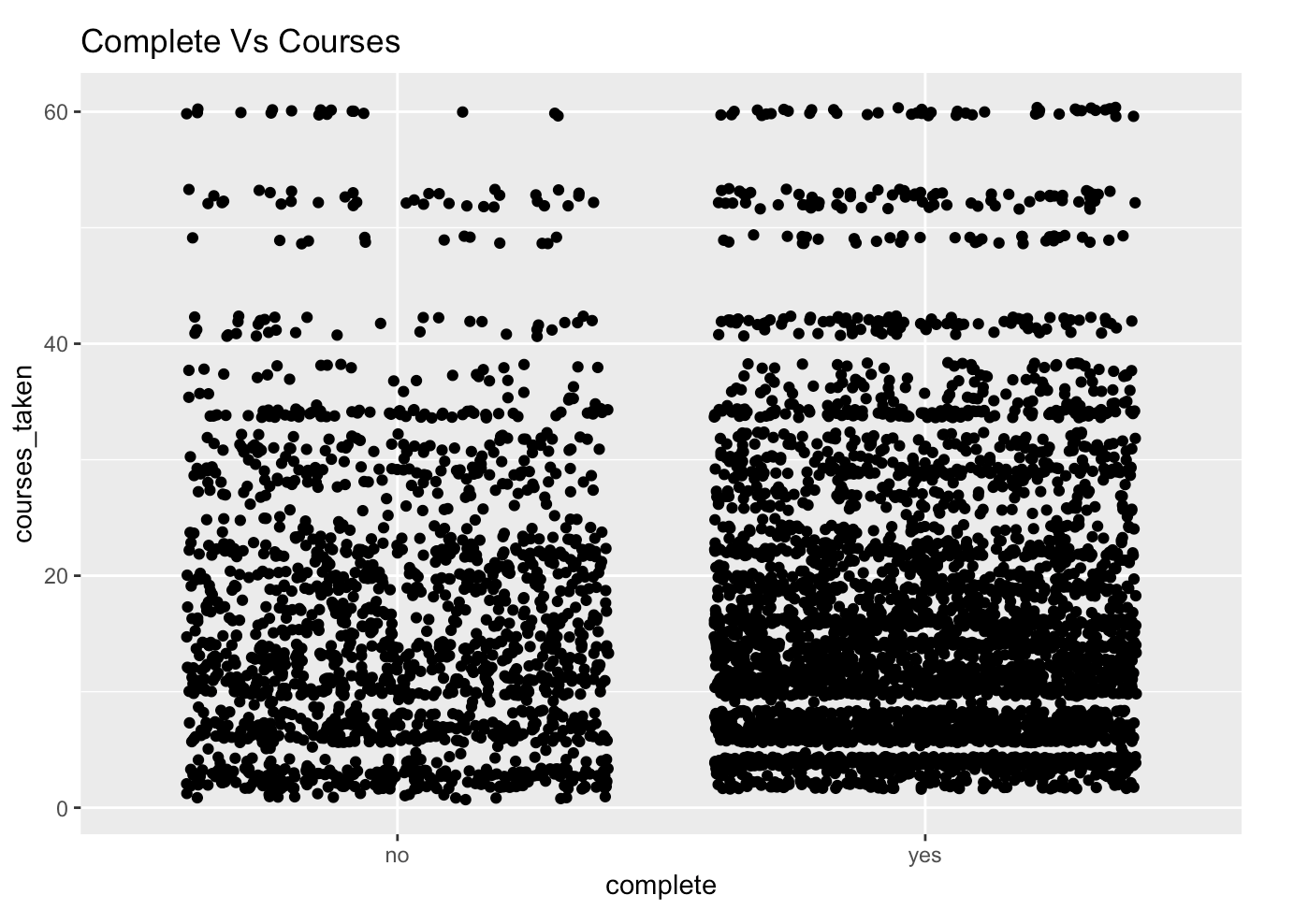
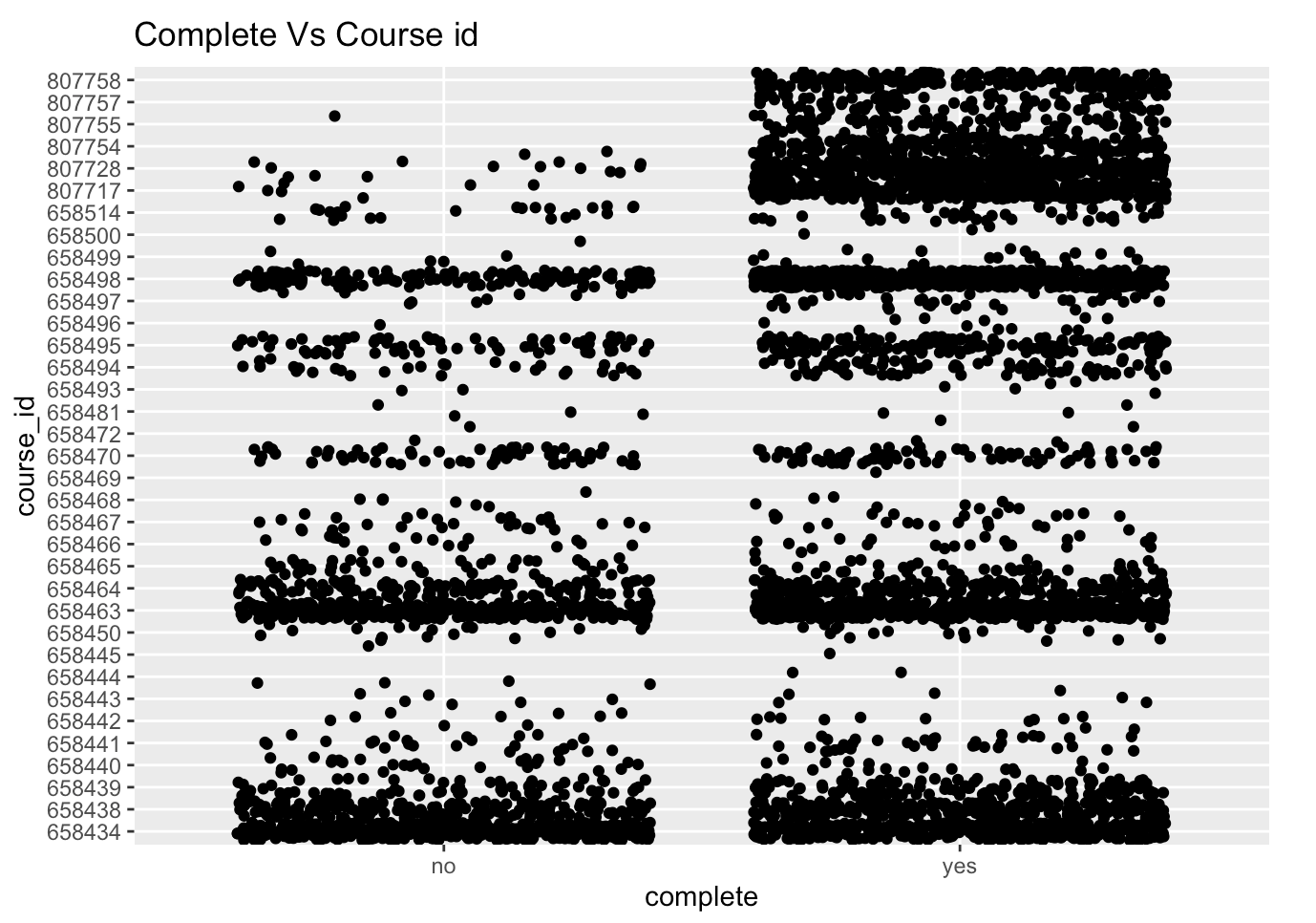
We then clean and prepare our data for the three models, and generate summaries for each based on the parameter of Accuracy of the model.
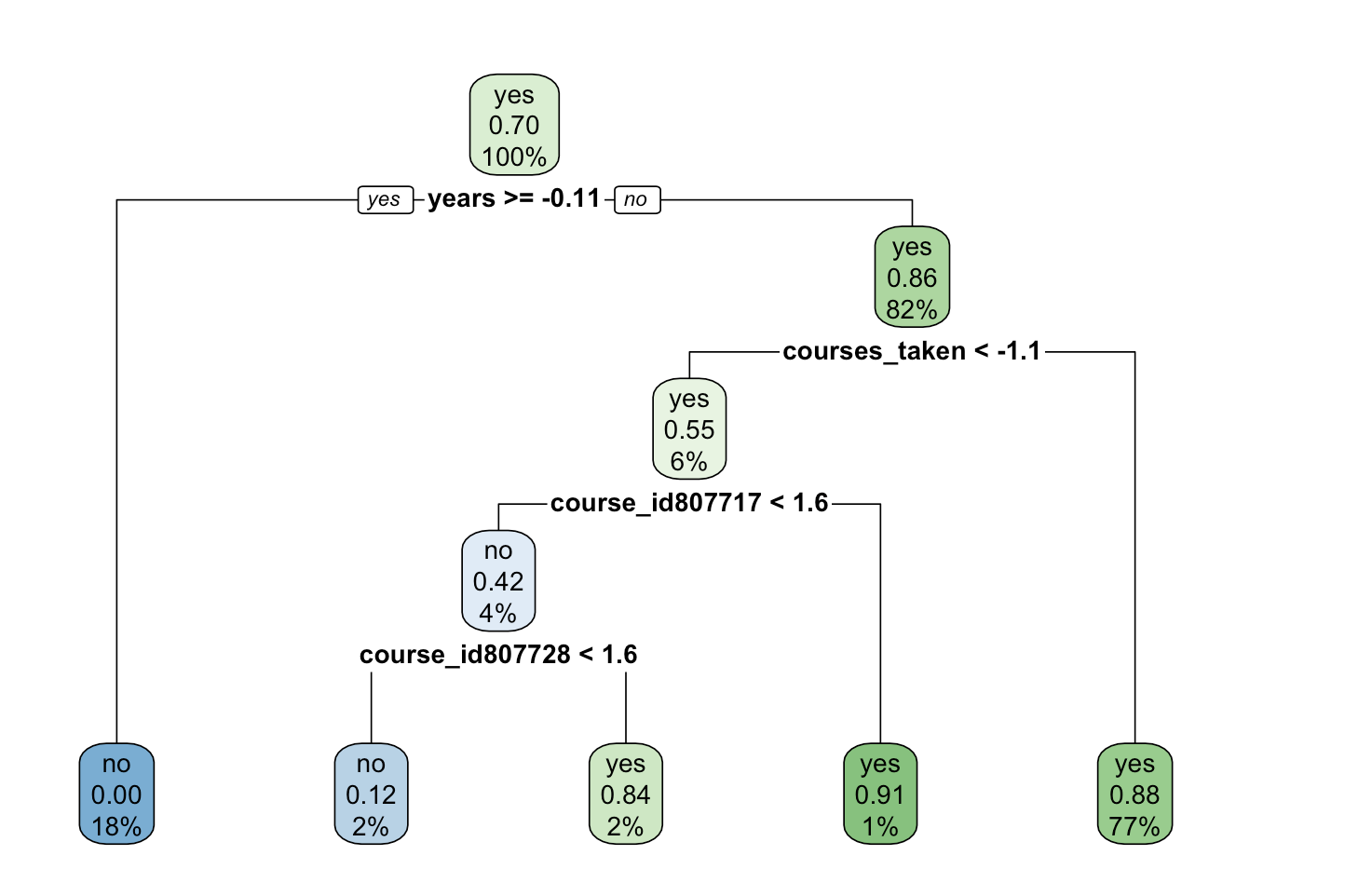

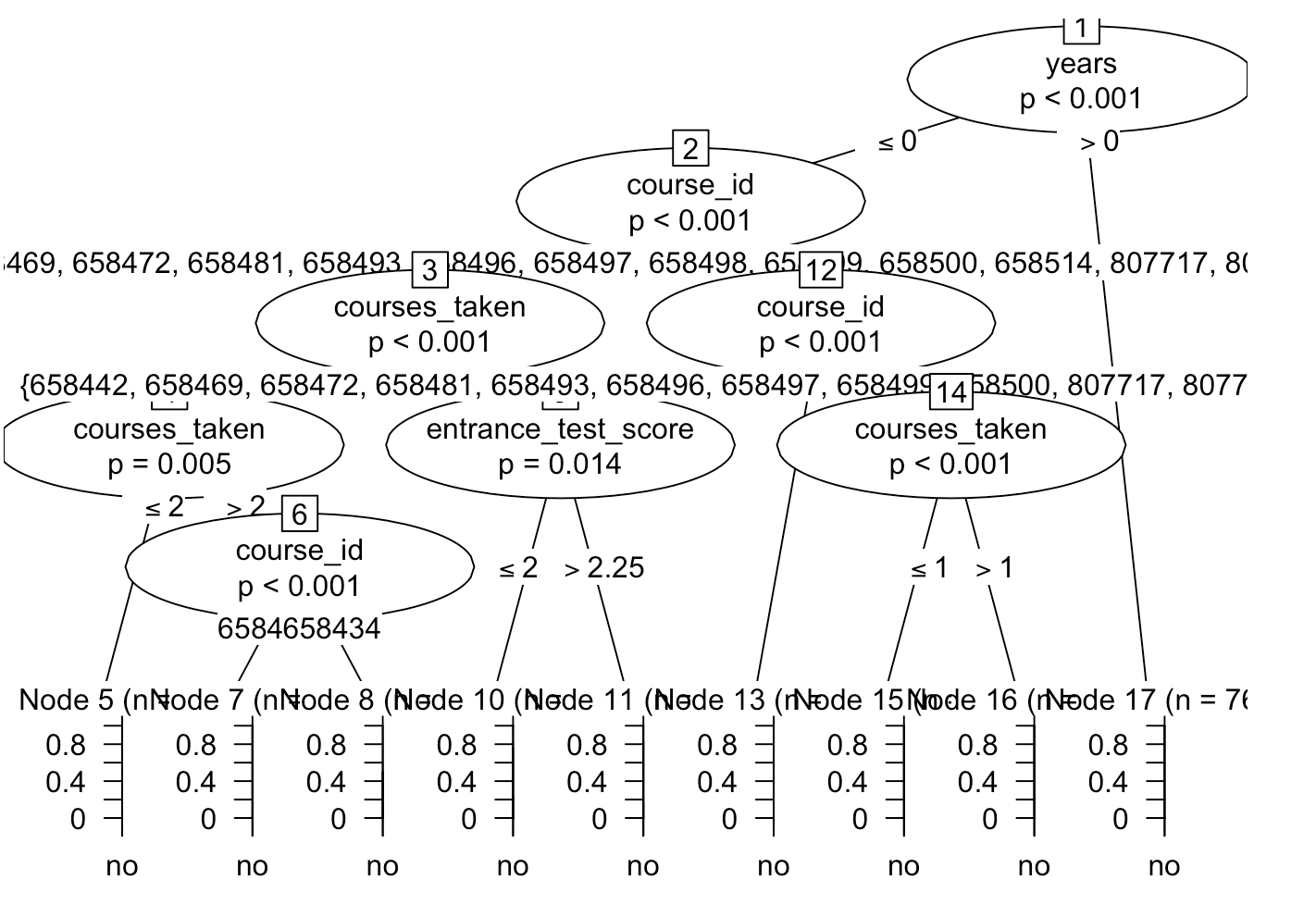


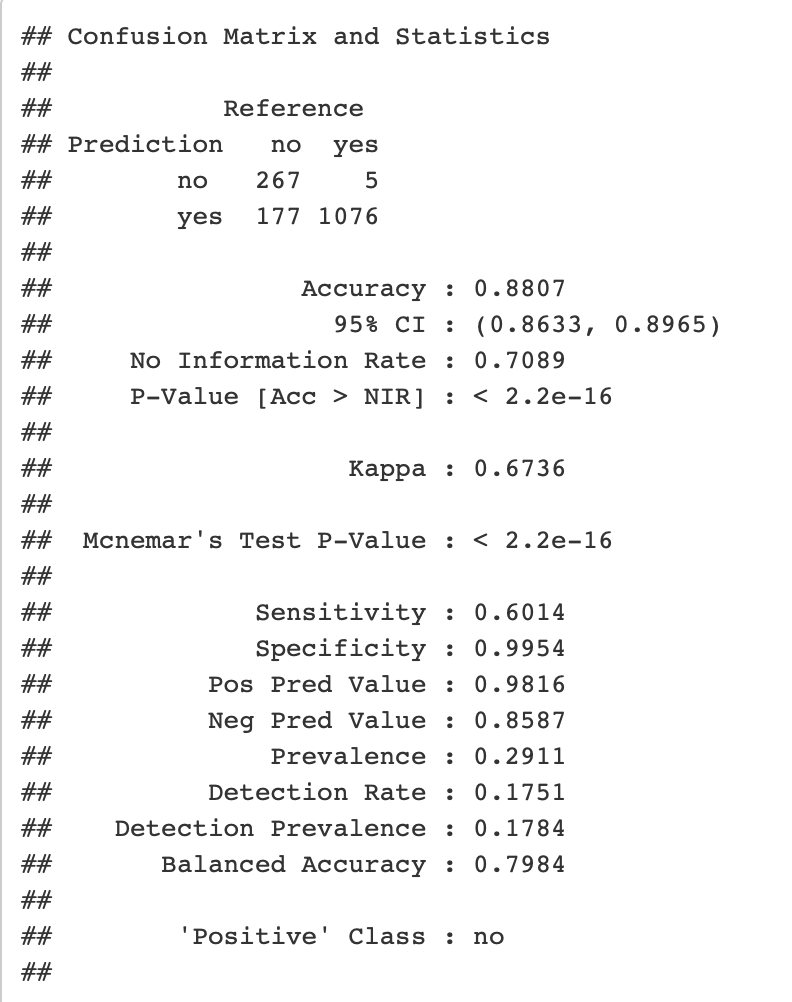
A comparison of the different models are seen in this graph, as well as in the RMD and HTML files in this repository.
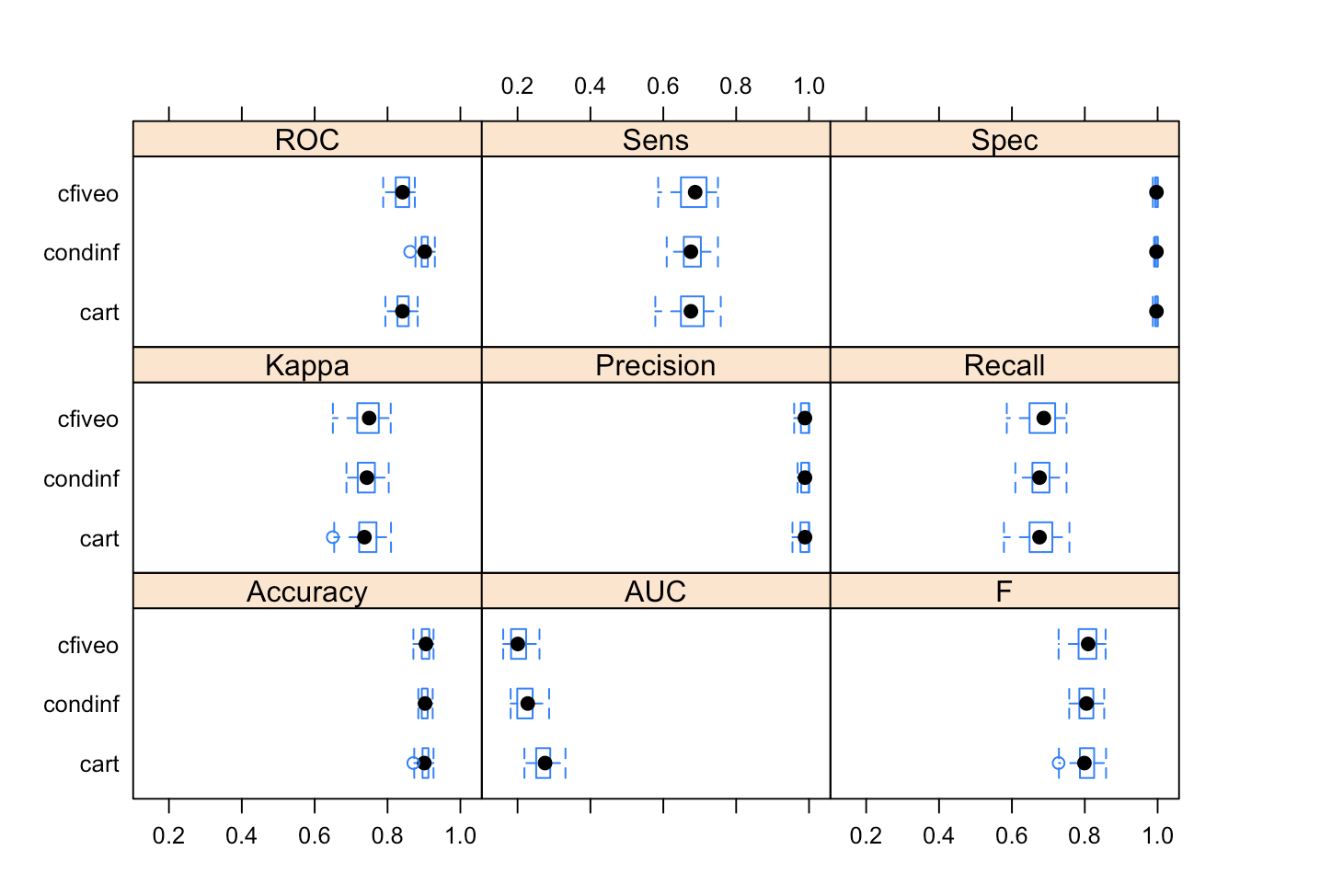
These models provide different accuracy rates and the best out of them is seen to be the Conditional Inference Model. This model could be used for the most accurate predictions of students who are likely to complete courses they have enrolled into, and could solve the problem of optimum allocation of resources.
- Predictions provide a wide array of benefits and can be utilized across different industrial and service sectors.
- Accuracy of different models of prediction can be sharpened by selecting variables of interest from a large dataset, and then running them through different packages for more customised results.
- The type of variables within the available data expand the horizons on the different prediction models which are possible and suitable, based on which further investigation can be carried out beyond Classification Tree models.
- R and R Studio
- R packages
- Git
- GitHub
Vidya Madhavan, MS candidate for Learning Analytics, Teachers College, Columbia University